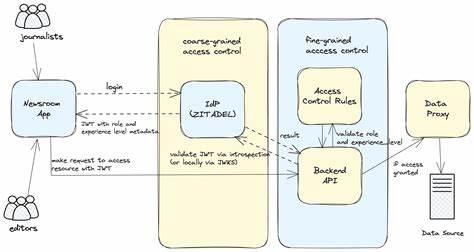
Die Entwicklung künstlicher Intelligenz im Bereich des Gesellschaftsspiels Go zeigt eindrucksvoll, wie sich die Lösung komplexer und unscharf definierter Probleme im Laufe der letzten Jahrzehnte gewandelt hat. Go ist ein traditionelles Brettspiel mit einfachen Spielregeln, einem 19x19-Gitter und dennoch einer enorm komplexen Spieltiefe, die sowohl menschliche als auch maschinelle Spieler vor große Herausforderungen stellt. Die Analyse der technischen Fortschritte von den frühen Expertensystemen wie GnuGo bis hin zu den jüngsten Erfolgen von AlphaGo Zero bietet wertvolle Erkenntnisse darüber, wie man schwierige Probleme in unterschiedlichen Bereichen der künstlichen Intelligenz erfolgreich angehen kann. Von digitalen Assistenten über selbstfahrende Autos bis hin zu komplexen Robotiksystemen sind viele moderne Herausforderungen dadurch gekennzeichnet, dass sie unscharfe oder nur unvollständig definierte Problemstellungen besitzen und einen enorm großen Lösungsraum abdecken. Go ist in dieser Hinsicht ein idealer Testfall, da trotz einfacher Grundregeln und leicht verständlichen Spielmechanismen strategische Tiefe und ganzheitliches Denken grundlegend sind, um Erfolg zu haben.
Die Anfänge der Computer-Go-Forschung waren geprägt von der Entwicklung handkodierter Expertensysteme. GnuGo, ein bekanntes Beispiel aus dieser Phase, basierte auf zahlreichen Regelwerken, Heuristiken und Entscheidungsbäumen, die von menschlichen Experten erarbeitet wurden. Dabei wurden typische Spielkonzepte wie „Drachen“, „Augen“ oder lokale Kampfstrukturen in Softwaremodule gegossen, die anhand von festgelegten Wenn-Dann-Bedingungen spielentscheidende Züge bewerteten. Trotz der klar formulierten Regeln stieß diese Herangehensweise bald an ihre Grenzen, da das System stark auf lokale Muster fixiert war und die Wechselwirkungen auf dem gesamten Brett oft vernachlässigte. Außerdem führten starre Vorgaben und eine fehlende Flexibilität dazu, dass das Programm viele Züge machte, die aus der Sicht menschlicher Spieler ineffizient oder sogar suboptimal wirkten.
In der Praxis spielte GnuGo ungefähr auf dem Niveau von durchschnittlichen Gelegenheitsspielern, was zeigte, dass reine Expertenheuristiken allein nicht ausreichen, um das komplexe strategische Puzzle Go zu lösen. Parallel zu diesen Entwicklungen im Bereich der handkodierten Regeln revolutionierte die Einführung von Monte-Carlo Tree Search (MCTS) den Bereich der Computer-Go-Strategien. MCTS ist ein probabilistisches Verfahren, das den Spielbaum dynamisch untersucht und unter Verwendung von Zufallssimulationen im Tree-Search-Ansatz die vielversprechendsten Züge priorisiert. Im Gegensatz zu klassischen Minimax-Algorithmen oder starren heuristischen Ansätzen ermöglicht MCTS das Durchsuchen und Bewerten großer Teilbäume mit hoher Effizienz. Die Integration von MCTS mit einfachen Rollout-Simulationen – „zufälligen“ Spielen bis zum Ende – ermöglichte eine deutlich realistischere Einschätzung der vorteilhaftesten Züge.
Zwar wies der Monte-Carlo Ansatz Schwächen bei taktischen Feinheiten auf, doch sorgte er für einen gewaltigen Sprung in der Spielstärke. MCTS-basierte Computerprogramme erreichten damit schon bald die Spielstärke von starken Amateuren und konnten herkömmliche Expertensysteme weit hinter sich lassen. In den darauffolgenden Jahren etablierte sich der Durchbruch des Deep Learning als neuer Standard in der KI-Forschung für Go. Die Idee war, Convolutional Neural Networks (CNN) zum Erlernen von Mustererkennung und Bewertung von Go-Positionen einzusetzen. Im Vergleich zu vorigen Methoden konnten neuronale Netze nicht nur heuristische Muster erfassen, sondern komplexe Zusammenhänge selbstständig erkennen und generalisieren.
Das bemerkenswerte Ergebnis war, dass solche Netzwerke bereits ohne baumbasierte Suche auf menschlichem Niveau spielen konnten. AlphaGo, das von DeepMind entwickelte Programm, kombinierte diesen Ansatz mit MCTS und setzte drei spezialisierte neuronale Netze ein: ein Vorschlagsnetzwerk für Züge, ein Bewertungsnetzwerk zur Einschätzung der Position und ein Netz zur Beschleunigung von Simulationen. AlphaGo spielte dank dieser Kombination schon auf dem Niveau sehr starker menschlicher Spieler und überraschte mit seinem intuitiven Stil und kreativen Spielzügen, welche menschlichen Experten neue Einsichten in das Brettspiel Go ermöglichten. Im weiteren Verlauf ließ sich jedoch feststellen, dass der von AlphaGo genutzte Prozess stark ressourcenintensiv war und noch menschliche Partien als Grundlage für das Training erforderte. Die nächste große Revolution kam mit der Entwicklung von AlphaGo Zero und danach von Programmen wie Leela Zero, die vollständig auf selbstständiges Lernen durch Reinforcement Learning setzen.
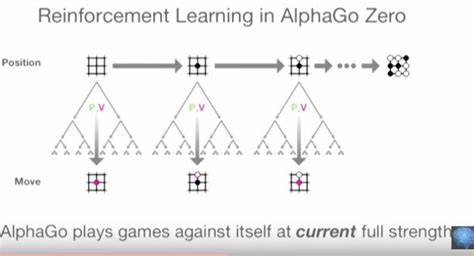
Das bedeutet, die KI beginnt völlig ohne menschliches Fachwissen und generiert das eigene Trainingsmaterial durch Selbstspiel. Dadurch fallen menschliche Datenquellen und Vorurteile weg und der Computer kann durch massive Parallelrechnungen und schrittweises Verbessern eigene Strategien entdecken, die oft überraschend und hoch effizient sind. AlphaGo Zero erreichte in kürzester Zeit eine Spielstärke, die alle bisherigen Modelle übertraf und demonstrierte eindrucksvoll das Potenzial von Reinforcement Learning kombiniert mit effizientem Baumdurchsuchen. Doch dieser Fortschritt kam nicht über Nacht und erforderte zahlreiche Iterationen, Fehlerkorrekturen und den Aufbau robuster Monitoring- und Analysewerkzeuge, um Erkenntnisse über das Verhalten eines komplexen Systems zu erlangen. Die historische Entwicklung von Go-KI zeigt klar, wie wichtig es ist, schwierige Probleme in Stufen zu bearbeiten.
Eine reine Abkürzung hin zu den komplexesten Methoden wie Reinforcement Learning lohnt sich selten ohne ausreichende Vorbereitung und stabile Grundlagen. Statt direkt ins letzte Stadium zu springen, ist es empfehlenswert, klassisches Suchverfahren mit heuristischen oder maschinell gelernten Modellen zu kombinieren und in iterativen Verbesserungszyklen fortzuschreiten. Jede Phase benötigt spezifische Infrastruktur, leistungsfähige Entwicklungsumgebungen und gründliches Monitoring, um Fehler frühzeitig zu erkennen und den Lernprozess kontrolliert zu gestalten. Diese Erkenntnisse aus der Computer-Go-Forschung sind auf andere technische und gesellschaftliche Felder übertragbar. Ob beim Entwickeln von autonomen Fahrzeugen, fortschrittlichen digitalen Assistenten oder komplexen Robotiksystemen – eine schrittweise Herangehensweise, die von einfachen Funktionen über maschinelles Lernen zu vollautomatischer Optimierung mit Reinforcement Learning führt, sollte bevorzugt werden.
Ein weiterer wichtiger Punkt ist die Akzeptanz, dass Wissensbasierte Expertensysteme zwar im Mittel kurzfristig Vorteile bringen, langfristig jedoch von Algorithmen verdrängt werden, die stärker mit Rechenleistung und selbstständigem Lernen skalieren. Auch wenn diese Entwicklung manchmal den Verlust etablierter Fachkompetenz bedeuten kann, ermöglichen sie nachhaltige Fortschritte und letztlich Systeme mit übermenschlicher Qualität. Die Lehre vom berühmten „Bitter Lesson“ verdeutlicht, dass menschlicher Aufwand beim Programmieren von Heuristiken zwar attraktiv erscheint, auf Dauer jedoch dem Vorstoß durch leistungsfähige KI-Systeme mit wachsender Rechenkapazität unterliegt. Unterm Strich ist die Computer-Go-Geschichte somit ein Lehrstück dafür, wie Technik und Wissenschaft durch Experimentieren, Offenheit für neue Paradigmen und sorgfältiger Methodik tiefgreifende Herausforderungen meistern können. Die Verschiebungen von GnuGo über MCTS, Deep Learning bis zu Reinforcement Learning geben einen Fahrplan an die Hand, der auf vielfältige schwierige Problemstellungen angewendet werden kann.
Dabei zeigt sich, dass Fortschritt selten linear oder sofort erfolgt, sondern in einer Abfolge gut geplanter Entwicklungsstufen, die Wissensaufbau und Technologieintegration intelligent miteinander verbinden. Die Kombination aus algorithmischer Innovation, starker Rechenkapazität und der Fähigkeit, aus eigenen Erfahrungen zu lernen, erzeugt letztendlich schlagkräftige KI-Systeme, die menschliches Niveau nicht nur erreichen, sondern übertreffen – eine Erkenntnis mit enormer Bedeutung für alle, die an der Entwicklung modernster Technologien arbeiten.