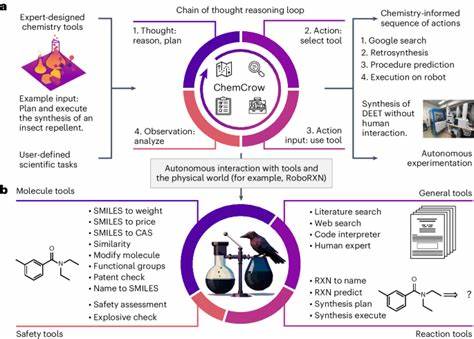
Die moderne Chemie ist eine Wissenschaft, die nicht nur auf Experimenten basiert, sondern auch von Wissen und intuitivem Denken getragen wird. In den letzten Jahren erlebte die Welt der künstlichen Intelligenz eine rasante Entwicklung, insbesondere im Bereich der großen Sprachmodelle (LLMs, Large Language Models). Diese Modelle können menschliche Sprache verarbeiten und komplexe Fragen beantworten, was die chemische Forschung und Lehre revolutionieren könnte. Doch wie gut sind diese Sprachmodelle wirklich im Verständnis und der Anwendung von chemischem Wissen? Und wie schlagen sie sich im Vergleich zu menschlichen Chemieexperten? Eine aktuelle Studie liefert spannende Antworten und öffnet den Raum für eine tiefgreifende Diskussion über die Rolle von künstlicher Intelligenz in den chemischen Wissenschaften. Im Zentrum der Untersuchungen steht ein neu entwickeltes Benchmark-Framework namens ChemBench.
Dieses umfangreiche Bewertungssystem umfasst über 2700 sorgfältig kuratierte Fragen aus verschiedenen Bereichen der Chemie, die unterschiedliche Schwierigkeitsgrade und Kompetenzen wie Wissen, logisches Denken, Berechnungen und Intuition abdecken. So können die Fähigkeiten von LLMs präzise und systematisch gemessen werden. Dabei wurde nicht nur die Performance von führenden open- und closed-source-Modellen bewertet, sondern auch die Expertise von Chemikern in vergleichbaren Tests erfragt. Die Ergebnisse überraschen: Einige der besten Sprachmodelle übertreffen im Durchschnitt sogar die Leistung der besten menschlichen Chemiker bei den gestellten Aufgaben. Dies unterstreicht das enorme Potential, das künstliche Intelligenz für die wissenschaftliche Arbeit darstellt.
Es zeigt auch, dass LLMs inzwischen eine Wissensbasis besitzen, die weit über einfache Textwiedergabe hinausgeht und einschlägige chemische Inhalte auch in komplexeren Zusammenhängen verarbeiten können. Doch dieser Fortschritt bringt gleichzeitig Herausforderungen mit sich. Die Modelle tun sich bei manchen grundlegenden Fragestellungen schwer, liefern teilweise falsche, aber übermäßig selbstsichere Antworten, und können ihre eigene Unsicherheit nur unzureichend reflektieren. Die Variabilität in den Ergebnissen wird auch in den verschiedenen chemischen Fachgebieten deutlich. Während allgemeine und technische Chemie von den Modellen verhältnismäßig gut gemeistert werden, zeigen Themen wie Toxikologie, Sicherheitsfragen oder analytische Chemie größere Schwächen.
Besonders komplexe Aufgaben wie die Interpretation von Kernspinresonanzspektren oder die Ermittlung der Anzahl unterschiedlicher Signale in Molekülen bleiben eine Herausforderung. In solchen Fällen fehlt den Modellen oftmals das tiefere strukturchemische Verständnis, das selbst erfahrenen Chemikern mit Zeichnungen oder Modellen gegeben ist. Ein Grund dafür könnte sein, dass viele Modelle Moleküle in Form von linearen Strings (zum Beispiel SMILES) anstelle von dreidimensionalen oder graphbasierten Repräsentationen erhalten, was die Erfassung räumlicher Informationen erschwert. Ein weiterer spannender Aspekt ist die fehlende Übereinstimmung bei der Bewertung von chemischen Präferenzen, wie sie beispielsweise für Wirkstoffentwicklung oder Materialoptimierung relevant sind. Während Chemiker in diesen Fragestellungen meist konsistente Urteile fällen, tendieren die Sprachmodelle dazu, Entscheidungen nahe am Zufall zu treffen.
Das deutet darauf hin, dass KI-Systeme zwar Wissen gut verarbeiten können, aber noch Probleme haben, abstrakte, subjektive oder domänenspezifische Präferenzen zu modellieren. Hier könnten gezieltes Training oder eine Integration menschlicher Feedbackmechanismen den Fortschritt fördern. Die Studie zeigt auch, dass die Größe der Sprachmodelle in einem gewissen Maße mit der Leistung korreliert. Größere Modelle erzielen tendenziell bessere Ergebnisse, was auf ein besseres Verständnis und einen breiteren Wissensspeicher schließen lässt. Gleichzeitig bedeutet dies jedoch auch höhere Rechenkosten und eine größere Notwendigkeit für spezialisierte Hardware und Infrastruktur.
Aus sicherheits- und ethischer Perspektive sind diese Fortschritte nicht unproblematisch. Der Zugang zu fortschrittlichen chemischen Informationen und Fähigkeiten könnte missbraucht werden, etwa für die Entwicklung gefährlicher Substanzen. Zudem nutzen nicht nur Experten, sondern auch beispielsweise Studierende oder Laien solche Tools, was das Potenzial für Fehlinformationen erhöht. Besonders die Tatsache, dass die Modelle ihre Unsicherheiten oft nicht realistisch einschätzen, kann in kritischen Situationen zu falschen Entscheidungen führen. Deshalb rufen die Ergebnisse der Studie zu verstärkter Forschung in Richtung Modell-Transparenz, verantwortungsvoller Nutzung und besserer Integration in den wissenschaftlichen Alltag auf.
Die Erkenntnisse legen nahe, dass die traditionelle Chemieausbildung und -prüfung sich weiterentwickeln muss. Wenn Sprachmodelle Faktenwissen und standardisierte Aufgaben mühelos bewältigen, rücken kritisch-logisches Denken, experimentelle Kreativität und die Interpretation komplexer Zusammenhänge als zentrale Kompetenzen in den Fokus. Künftige Lernkonzepte könnten die Zusammenarbeit von Mensch und KI stärker fördern, sodass die Stärken beider optimal genutzt werden. Technisch gesehen erlaubt das ChemBench-Framework eine flexible und detaillierte Bewertung von Modellen. Es berücksichtigt verschiedene Aufgabentypen, ermöglicht die Integration externer Werkzeuge wie Web-Suchmaschinen oder Rechenmodule und ist offen für Erweiterungen.
So kann es als zentraler Bezugspunkt für die Weiterentwicklung von KI-Systemen in der Chemie dienen. Darüber hinaus macht es die Leistungsfähigkeit von Modellen für Forscher und Entwickler transparent und vergleichbar. Insgesamt zeigt die Analyse der großen Sprachmodelle in der Chemie eine beeindruckende Leistung auf verschiedenen Ebenen, verbunden mit klaren Grenzen. Der Fortschritt ist vielversprechend, doch auch ernüchternd, wenn man sieht, dass Modelle trotz riesiger Datenmengen und Rechenleistungen noch nicht das holistische, flexible Denken eines erfahrenen Chemikers ersetzen können. Vielmehr könnten sie als intelligente Assistenten fungieren, die repetitive oder umfangreiche Recherchen übernehmen und so Expertinnen und Experten entlasten.
Die Zukunft der Chemie wird somit zunehmend durch die Interaktion von menschlichem Wissen und künstlicher Intelligenz geprägt sein. Ein gutes Verständnis der jeweiligen Stärken und Schwächen ist dabei entscheidend. Die Entwicklung besserer, sicherer und vertrauenswürdiger KI-Modelle sowie die Förderung der entsprechenden Kompetenzen in der Chemie-Ausbildung werden die Weichen für effektive Synergien stellen. Das ChemBench-Projekt stellt in diesem Prozess ein wertvolles Werkzeug und wegweisendes Beispiel dar.