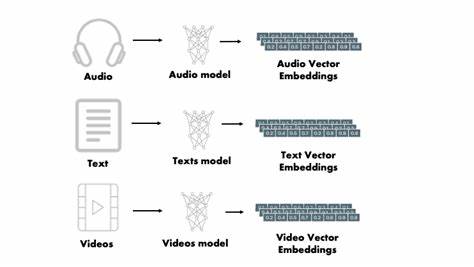
Die Welt der künstlichen Intelligenz und insbesondere des maschinellen Lernens erfährt durch die Nutzung von Embeddings einen tiefgreifenden Wandel. Embeddings sind mathematische Repräsentationen von Datenpunkten, die es ermöglichen, komplexe Informationen wie Sprache, Bilder oder Musikstücke in Vektorform darzustellen. Vor allem in Sprachmodellen und Recommender-Systemen eröffnen Embeddings vielseitige Anwendungsmöglichkeiten. Ein spannender neuer Ansatz ist das Interpolieren zwischen zwei Embeddings, um damit neue Inhalte oder Übergänge zu generieren. Das LLM-interpolate CLI Tool ist hier eine innovative Lösung, die speziell für Benutzer des LLM-Frameworks entwickelt wurde.
Es vereinfacht das Erzeugen von Zwischenpunkten zwischen Embeddings und ermöglicht so kreative Anwendungen und praktische Nutzungsszenarien. Das grundlegende Konzept hinter LLM-interpolate ist einfach aber wirkungsvoll. Wenn man zwei Datenpunkte als Vektoren innerhalb eines hochdimensionalen Raums vorliegen hat, kann man diese Vektoren miteinander interpolieren, also schrittweise Zwischenwerte berechnen, die sich entlang der Route von einem zum anderen bewegen. Die Berechnung dieser Zwischenpunkte erfolgt mathematisch gesehen über gewichtete Mittelwerte der Vektorkoordinaten und erzeugt eine Art „Kontinuum“ zwischen den ursprünglichen Punkten. Solche interpolierten Embeddings können als Repräsentationen von neuartigen, hybriden Inhalten interpretiert werden, die Merkmale beider Endpunkte enthalten.
Die Nutzung von LLM-interpolate bietet hierbei mehrere Vorteile. Zum einen ist es nahtlos in das LLM Ökosystem integriert und lässt sich über die Kommandozeile bedienen, was eine einfache Automatisierung für Entwickler und Forschungsteams ermöglicht. Zum anderen ist es flexibel, da es beliebige Embedding-Kollektionen ansprechen kann, sofern diese in der Datenbank des LLM-Frameworks eingebettet sind. Beispielsweise können Musiktitel, Textdokumente oder auch Bildbeschreibungen als Grundlage genommen werden, um darauf aufbauend fließende Übergänge oder neuartige Inhalte zu schaffen. Ein typischer Anwendungsfall ergibt sich in der Musikindustrie oder bei Playlists.
Mit Embeddings, die auf musikalischen Merkmalen beruhen, lassen sich Songs nicht nur klassifizieren, sondern auch durch Interpolation neue Hörwege entdecken. Man könnte beispielsweise zwischen einem Hip-Hop-Song und einem Country-Song mehrere Zwischenschritte erzeugen, die akustisch und stilistisch sanfte Übergänge schaffen. So wird aus einer vermeintlich widersprüchlichen Musikmischung eine harmonische Playlist, die den Hörer auf eine Reise durch verschiedene Genres mitnimmt. Mit der Verfügungstellung geeigneter Embeddings, etwa durch Modelle wie CLAP, lässt sich diese Technik leicht umsetzen. Die Installation von LLM-interpolate ist unkompliziert, insbesondere wenn bereits das LLM-Framework genutzt wird.
Der Befehl llm install llm-interpolate bringt das Plugin in die bestehende Umgebung. Wurden Embeddings in einer Kollektion mit beispielsweise llm embed-multi erzeugt, kann die Interpolation sofort mit dem Befehl llm interpolate aufgerufen werden. Parameter wie die Anzahl der Zwischenpunkte sind einstellbar, so dass der Anwender die Granularität der Übergänge individuell festlegen kann. Auch unterschiedliche Embeddings-Datenbanken lassen sich über entsprechende Optionen ansprechen, was einen hohen Grad an Anpassbarkeit sicherstellt. Neben musikalischen Anwendungen bietet LLM-interpolate auch spannende Perspektiven im Bereich der Sprachverarbeitung und semantischen Textanalyse.
Wird ein Textkorpus mit einem Embedding-Modell in eine Sammlung eingespeist, kann man zwischen zwei bestimmten Textabschnitten interpolieren, um neue, semantisch verwandte Inhalte zu generieren oder um graduelle Übergänge zwischen Themengebieten zu erkunden. Dies eröffnet neuartige Möglichkeiten bei der Textgenerierung, Inhaltsanalyse und beim Auffinden von Dokumenten mit semantischer Nähe. Somit fungiert LLM-interpolate nicht nur als Werkzeug, sondern als Brücke zwischen Bits und Bedeutung. Die Grundlage für die guten Ergebnisse von LLM-interpolate ist ein robuster Embedding-Vektorraum. Verschiedene Modelle wie CLAP, OpenAI-Embeddings oder andere spezialisierte Algorithmen können als Basis dienen.
Ebenfalls sollte eine sinnvolle Kollektion angelegt sein, da die Qualität der Interpolation stark von der Homogenität und Diversität der Ausgangsdaten abhängt. Dabei ist nicht nur die technische Implementierung entscheidend, sondern auch die sorgfältige Auswahl und Vorbereitung der Daten, um möglichst realistische und ansprechende Zwischenpunkte zu erzeugen. Für Entwickler und Teams, die mit Machine Learning und KI arbeiten, bietet LLM-interpolate einen praktischen und leicht zugänglichen Weg, um das Potenzial von Embeddings voll auszuschöpfen. Die Möglichkeit, Übergänge systematisch und kontrolliert zu erstellen, erlaubt neue Ideen für Anwendungen in personalisierten Empfehlungen, künstlerischen Kreationen, Forschung und mehr. Die Integration in gängige Softwarepipelines und die offene Bereitstellung als Plugin sichern eine nachhaltige Nutzung und Weiterentwicklung.
In der Praxis kann man den Workflow von der Erstellung der Embeddings bis zur Interpolation in wenigen Schritten zusammenfassen. Nach dem Einbetten der Ausgangsdaten in eine Datenbank werden zwei Referenzpunkte ausgewählt, die als Anfang und Ende dienen. Daraufhin generiert das Tool eine Anzahl interpolierter Punkte, die als Ausgangswerte für weitere Prozesse oder Analysen verwendet werden können. Neben der direkten Ausgabe ist auch eine Weiterverarbeitung denkbar, etwa durch Visualisierung im Vektorraum oder Anwendung in KI-generierten Content-Systemen. Die Anwendungsmöglichkeiten von LLM-interpolate sind vielfältig und reichen weit über einfache Playlist-Gestaltung hinaus.