Retrieval Augmented Generation, kurz RAG, hat sich in den letzten Jahren als eine der effektivsten Methoden zur Integration von großen Sprachmodellen (LLMs) in reale Anwendungen etabliert. Dieser Ansatz kombiniert die Stärke von vortrainierten Sprachmodellen mit relevanten, dynamisch abgerufenen Informationen aus eigenen Wissensdatenbanken. Vor allem für Unternehmen bietet RAG einen cleveren Weg, um KI-Antworten zu präzisieren, ungewollte Fehlinformationen zu vermeiden und das Wissen flexibel zu erweitern. Doch ein einfaches, generisches RAG-System ist oft nur der Anfang einer erfolgreichen KI-Reise. Die wahre Königsdisziplin liegt in der individuellen Anpassung und Erweiterung dieser Grundstruktur.
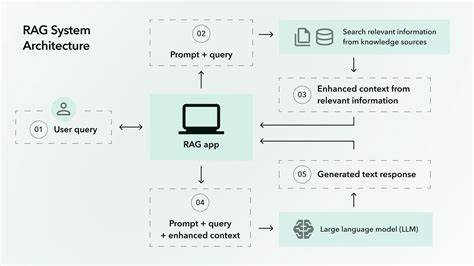
Diese ermöglicht Unternehmen, maßgeschneiderte Lösungen zu schaffen, die genau auf ihre Bedürfnisse und Herausforderungen eingehen. Die Basis eines RAG-Systems besteht in mehreren Kernkomponenten. Zunächst gibt es den sogenannten Retriever. Er funktioniert wie eine intelligente Suchmaschine, die aus einem großen Dokumentenbestand die passendsten Informationen für eine Nutzereingabe selektiert. Danach folgt das Prompting, wobei eine Schnittstelle die Suchergebnisse gemeinsam mit der ursprünglichen Nutzeranfrage für die Verarbeitung durch das LLM aufbereitet.
Anschließend wird über einen API-Connector die generative KI angesprochen, die auf Grundlage des Kontextes eine Antwort generiert. Dieses klassische Setup ist straightforward und für viele einfache Anwendungsfälle ausreichend, beispielsweise für Frage-Antwort-Systeme, bei denen es wichtig ist, dass Antworten auf überprüfbaren Informationen basieren statt nur auf dem vortrainierten Wissen. Doch gerade an diesem Punkt wird schnell deutlich, dass eine starre Umsetzung nicht immer genügt. Der Markt und die Anforderungen von Unternehmen sind vielschichtig. Verschiedene Fachbereiche, unterschiedliche Datenarten und vielfältige Fragestellungen verlangen nach Flexibilität und Erweiterbarkeit.
Deshalb gewinnt das Konzept der Modularität enorm an Bedeutung. Hier setzt die Idee des Compound AI-Ansatzes an, der die einzelnen Komponenten eines RAG-Systems nicht als fix festgelegte Bausteine betrachtet, sondern als modulare Elemente, die flexibel erweitert, ersetzt oder ergänzt werden können. So lässt sich das RAG-Pipeline-Design passgenau auf spezielle Geschäftsbedürfnisse zuschneiden. Ein wesentliches Element für die Anpassung eines RAG-Systems ist der Einsatz eines Query Classifiers vor der eigentlichen Dokumentenabrufphase. Dieser intelligent filtert oder kategorisiert eingehende Nutzeranfragen.
So kann die Pipeline dynamisch entscheiden, welchen Weg die Anfrage einschlagen soll, etwa um unerwünschte Eingaben, sogenannte Prompt Injection-Attacken, zu verhindern oder um Anfragen, die thematisch nicht zum System passen, frühzeitig auszusortieren. Zugleich ermöglicht ein gut trainierter Query Classifier eine agentische Verhaltensweise, indem er verschiedene Verarbeitungspfade in der Pipeline je nach Anfrageart auswählt. Das erhöht nicht nur die Sicherheit, sondern auch die Präzision der Antworten erheblich. Während der Retrieval-Phase profitieren individuell gestaltete RAG-Systeme von hybriden Suchansätzen, die mehrere Retrieval-Methoden kombinieren. So lassen sich semantische und keyword-basierte Verfahren parallel einsetzen.
Während semantische Retriever Dokumente nach deren inhaltlicher Bedeutung suchen, greifen keyword-basierte Ansätze auf die exakte Übereinstimmung von Begriffen zurück. Die Kombination beider Verfahren sichert eine wesentlich robustere und diversifiziertere Ergebnismenge. Zusätzlich kann der Einsatz fortschrittlicher Techniken wie HyDE (Hypothetically Document Embeddings) die Genauigkeit weiter steigern, indem hypothetische Vektor-Repräsentationen generiert und für die Suche eingesetzt werden. Wer komplexe Multimodalität benötigt, etwa das Abrufen von Bildern, Audiodateien oder die Verarbeitung von Tabellen über Text-zu-SQL-Methoden, kann diese in den Retrieval-Prozess integrieren und so die Breite der abgedeckten Informationsquellen deutlich erweitern. Nach dem Abruf der Dokumente spielt das Ranking der Resultate eine entscheidende Rolle.
Zwar liefern Retriever eine Vorauswahl relevanter Informationen, doch deren Reihenfolge ist nicht immer optimal für das LLM. Ein spezieller Ranker verfeinert die Auswahl, indem er Dokumente besser nach Relevanz bewertet. Dies kann durch komplexe Modelle geschehen, die die inhaltliche Nähe der Ergebnisse prüfen, oder über Metadaten, wie Publikationsdatum, Autorenschaft oder Themenzugehörigkeit. Das Ranking spart letztlich Kosten und Rechenzeit, indem das LLM nur mit den wichtigsten Dokumenten konfrontiert wird. Gleichzeitig steigt die Qualität der generierten Antwort, da irrelevante oder veraltete Daten aussortiert werden.
Eine weitere erweiterte Komponente ist die sogenannte Referenzvorhersage, die nach der Antwortgenerierung zum Tragen kommt. Ziel ist es, die Quellen der ausgespielten Informationen transparent zu machen. Nutzer können so nachvollziehen, auf welchen Dokumenten oder Textpassagen eine Aussage basiert. Einfach nur das LLM zu bitten, Quellen zu nennen, reicht oft nicht aus, da Modelle manchmal falsche oder ungenaue Referenzen generieren. Daher setzen fortschrittliche Systeme spezialisierte Modelle ein, die Satz für Satz analysieren und die tatsächlichen Ursprungsdokumente präzise erkennen.
Dies erhöht die Verlässlichkeit und das Vertrauen in die KI-Ergebnisse erheblich. In der Praxis zeigt sich, dass Firmen häufig mehrere Anpassungen miteinander kombinieren. Die Pipeline wird individuell gestaltet durch zusätzliche Schritte wie Query Expansion oder Query Transformation, die Suchanfragen erweitern oder umformulieren, um bessere Treffer zu erzielen. Retrieval selbst erfolgt häufig hybrid mit einer Kombination aus dichten vektorbasierten und sparsamen keyword-basierten Methoden. Dadurch entsteht ein maßgeschneidertes RAG-System, das nicht die Komplexität anstrebt, sondern Effizienz und Effektivität für den konkreten Anwendungsfall.
Der Entwicklungsprozess solcher Systeme ist meistens iterativ. Man startet mit einer Basisvariante, misst die Performance, sammelt Feedback und verbessert die einzelnen Komponenten Schritt für Schritt. Langfristige Projektzyklen mit ständiger Adaption sichern ab, dass die KI-Lösungen nicht nur technisch gut funktionieren, sondern auch in der Praxis echten Mehrwert schaffen und Wettbewerbsvorteile erzielen. Die Forschung und Entwicklung in diesem Bereich geht aber noch weit über die klassischen RAG-Modelle hinaus. Neue Architekturen wie Agentic RAG oder GraphRAG heben das bisher bekannte Konzept auf eine neue Ebene.
Agentic RAG etwa integriert eine agentenartige Intelligenz, die verschiedene Werkzeuge und Teilsysteme dynamisch aktiviert und kombiniert. Ein Beispiel wäre eine Fragestellung, die je nach Inhalt mittels einer statischen Firmen-Datenbank oder durch eine Online-Web-Recherche beantwortet wird. Durch diese Flexibilität sind solche Systeme bestens geeignet, um komplexe, offene Probleme mit adaptivem, strategischem Vorgehen zu lösen. GraphRAG hingegen nutzt die Fähigkeit von LLMs, Wissen graphisch zu strukturieren. Dabei werden Entitäten und deren Beziehungen aus Dokumentensammlungen extrahiert und in einem Wissensgraph abgebildet.
Für Anwendungsfelder, in denen das Verstehen von Zusammenhängen über Dokumentgrenzen hinweg essenziell ist – wie Finanzanalysen, juristische Bewertungen oder medizinische Forschung – eröffnen sich hierdurch tiefergehende Erkenntnisse und präzisere Antworten. Im Kern liegt die Zukunft von RAG-Systemen in der Kombination von Modularität, Skalierbarkeit und intelligenten Erweiterungen. Unternehmen, die diese Prinzipien verstehen und gezielt anwenden, können komplexe Wissenswelten sicher und effizient erschließen. Innovative Anpassungen machen RAG nicht nur zu einem Werkzeug für einfache Abfragen, sondern zu einem dynamischen, lernfähigen System, das sich stetig weiterentwickelt. Abschließend ist zu betonen, dass neben der Architektur der Pipeline auch die sorgfältige Vorbereitung und Indexierung der zugrundeliegenden Daten eine maßgebliche Rolle in der Optimierung von RAG-Systemen spielt.
Je besser die Datenquellen strukturiert, angereichert und gepflegt sind, desto effizienter und genauer kann das System arbeiten. Auch der Einsatz von Metadaten zur verbesserten Filterung und Clustering ist ein wichtiger Hebel für eine erfolgreiche Umsetzung. Für Unternehmen, die im KI-Bereich wirklich vorne mitspielen möchten, heißt es also: Nicht auf Standardlösungen zu setzen, sondern eigene Anwendungsfälle genau zu analysieren, geeignete Erweiterungen zu implementieren und durch einen agilen Entwicklungsprozess dauerhaft zu optimieren. So wird Retrieval Augmented Generation zu einem nachhaltigen Wettbewerbsvorteil und einem zentralen Baustein moderner KI-Infrastrukturen.