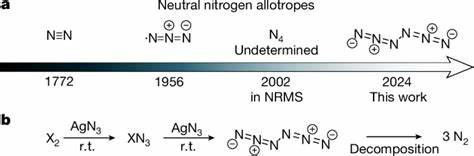
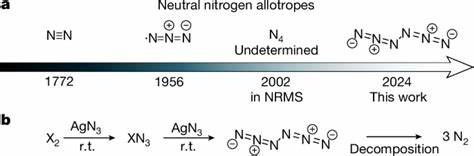
In der Welt der Webentwicklung und verteilten Systeme gehört der Umgang mit Fehlern und Überlastungen zu den größten Herausforderungen. Ein bewährtes Mittel, um temporäre Fehler abzufangen, sind Wiederholungsversuche, sogenannte Retries. Doch die konventionelle Weisheit, die auf exponentielles Backoff und Jitter setzt, stößt in modernen, komplexen Anwendungen zunehmend an ihre Grenzen. Dabei geht es nicht nur um die bloße Wiederholung von fehlgeschlagenen Anfragen, sondern um die intelligente Gestaltung dieser Prozesse, um sowohl die Stabilität als auch die Nutzererfahrung zu optimieren. Retrie-Mechanismen dienen vor allem dazu, temporäre Fehler wie Netzwerkprobleme oder kurze Dienstunterbrechungen zu handhaben.
Exponentielles Backoff in Kombination mit Jitter stellt sicher, dass wiederholte Anfragen nicht direkt hintereinander erfolgen, sondern sukzessive zeitlich gestreckt werden. Dadurch sollen Lastspitzen vermieden und die Wahrscheinlichkeit erhöht werden, dass die folgende Anfrage erfolgreich ist. Diese Taktik ist per se effektiv – zumindest in Szenarien mit begrenzter Client-Anzahl und überschaubaren Überlastsituationen. Allerdings zeigen reale Szenarien und moderne verteilte Systeme, dass diese Herangehensweise bei dauerhaftem oder schwerwiegendem Overload oft kontraproduktiv ist. Wenn eine Vielzahl von Clients oder Services ständig erneute Anfragen mit exponentiellem Aufschub absendet, kommt es zu einer Verlagerung der Last in die Zukunft, anstatt diese nachhaltig zu reduzieren.
Dies kann die Gesamtlast auf das System schlichtweg erhöhen und die Stabilität langfristig gefährden. Eine weit verbreitete Strategie zur Abmilderung von Fehlern sind Circuit Breaker. Sie erkennen wiederholt fehlschlagende Verbindungen und schalten Anfragen an überlastete oder ausgefallene Dienste ab, bevor weitere Ressourcen verschwendet werden. Circuit Breaker wirken dabei wie ein Schutzmechanismus: Sie wandeln partielle Fehler, die beispielsweise nur einen Bruchteil der Serviceaufrufe betreffen, in vollständige Fehler um, indem sie den Zugriff blockieren. Doch hier verbirgt sich eine wichtige Schwäche.
In verteilten Systemen sind Fehler oft partiell und fragmentiert. Manche Daten werden möglicherweise nur bei bestimmten Shards nicht gefunden oder Teile des Systems reagieren unterschiedlich. In solchen Umgebungen kann ein Circuit Breaker dazu führen, dass erfolgreiche Anfragen abgewiesen werden, schlicht weil ein anderer Teil kurzfristig ausgefallen ist. Die Folge sind potenzielle Fehlalarmen und mangelnde Systemverfügbarkeit trotz funktionierender Komponenten. Eine Umsetzung, die versucht, diesen Idealfall zu erfüllen, sieht vor, dass Circuit Breaker die Erst-Anfragen immer durchlassen und nur wiederholte Versuche anhand ihrer Entscheidungen blockieren.
Dies reduziert irrtümliche Blockierungen im frühen Stadium, nimmt aber den Circuit Breakern zugleich ihren großen Vorteil der schnellen Lastabschottung. In dieser Konstellation bleiben alternative Mechanismen wie sogenannte Token Buckets häufig die bessere Wahl. Token Buckets sind ein Konzept, bei dem die Rate von Anfragen kontrolliert wird, indem eine begrenzte Anzahl von Tokens ausgegeben wird, die einen Zugriff erlauben. Sobald die Tokens aufgebraucht sind, werden weitere Anfragen abgewiesen oder verzögert. Dieses Verfahren führt zu einem effektiven Lastschutz, da es die Anfragerate aktiv begrenzt.
Im Gegensatz zum Backoff kann ein Token Bucket die Last proaktiv drosseln, anstatt sie nur zeitlich zu verschieben. Der Einsatz von Token Buckets in Retry-Strategien erlaubt es, die Anzahl der Wiederholungsversuche zu begrenzen und somit eine zusätzliche Entlastung für das System zu schaffen. Damit wird verhindert, dass Dauerüberlastungen durch unkontrollierte Retrys noch verschärft werden. Gerade in Systemen mit vielen unabhängigen Clients hat sich diese Herangehensweise als besonders praktisch erwiesen. Grundsätzlich kann man den Umgang mit Retries anhand eines zweidimensionalen Modells verstehen.
Auf der einen Achse steht die Dauer der Überlast – kurzfristig oder langfristig – auf der anderen die Anzahl der Clients – wenige oder sehr viele. Bei einer kurzzeitigen Überlast helfen Backoff-Strategien effektiv, da sie den durch Retrys induzierten Traffic zeitlich aufsplitten und so die Lage entschärfen. Bei wenigen Clients mit langfristiger Überlast hilft Backoff ebenfalls, da die Verzögerung zukünftiger Anfragen die Gesamtlast reduziert. Wenn jedoch viele unabhängige Clients über einen langen Zeitraum das System beanspruchen, erweist sich Backoff als ineffizient. Die einzelnen Clients erfahren oft erst nach ihrer ersten Anfrage, dass das System überlastet ist.
Ihr Backoff verzögert lediglich die Bearbeitung, verringert nicht die Anzahl der Erst-Anfragen. Hier liegen die Schwächen des konventionellen Retry-Ansatzes. Die ungebremste Anzahl an Erst-Anfragen macht eine andere Herangehensweise notwendig, die nicht nur Wiederholungen, sondern auch die Eingangslast reduziert. Interessant sind auch praktische Erfahrungsberichte und Simulationen, die verschiedene Retry-Strategien vergleichen. Sie zeigen auf, wie unterschiedliche Policy-Varianten in Szenarien mit großen Client-Zahlen oder komplexen Lastverteilungen reagieren.
Diese Analysen helfen dabei, fundierte Entscheidungen für den Einsatz bestimmter Mechanismen zu treffen. Zudem beleuchten sie die ergänzende Rolle der sogenannten Deadline Propagation. Deadline Propagation beschreibt die Methode, in der jede Anfrage mit einem Timeout versehen wird, nach dessen Ablauf die Anfrage abgebrochen wird. Dies setzt klare zeitliche Grenzen für die Bearbeitung und verhindert, dass lange hängende Prozesse das System zusätzlich belasten. Deadline Propagation wirkt als Ergänzung zu Retry-Limits, kann diese aber nicht substituieren.
Sie sorgt für schnellere Fehlererkennung und besseres Ressourcenmanagement. Für Entwickler und Systemarchitekten empfiehlt es sich, Retry-Strategien stets kontextspezifisch zu gestalten. Die Einfachheit von exponentiellem Backoff und Jitter macht diese Mechanismen attraktiv für kleine Systeme oder temporäre Probleme. Komplexe und dauerhafte Szenarien hingegen benötigen differenziertere Lösungen. Token Buckets bieten hier ein wirkungsvolles Instrumentarium, um Überlastungen zu drosseln und die Systemverfügbarkeit zu erhöhen.
Zusammenfassend lässt sich festhalten, dass Retry-Mechanismen mehr sind als bloße Wiederholungen von fehlgeschlagenen Anfragen. Ihre intelligente Steuerung kann den Unterschied zwischen einem stabilen, belastbaren System und einem instabilen, durch Überlast gefährdeten Dienst ausmachen. Die Kombination aus Backoff, Circuit Breaker, Token Buckets und Deadline Propagation bildet dabei ein robustes Toolkit, das den Herausforderungen moderner verteilter Systeme gerecht wird. Im Zeitalter wachsender Nutzerzahlen, heterogener Dienste und verteilter Architekturen gewinnen diese Mechanismen zunehmend an Bedeutung. Ein fundiertes Verständnis ihrer Funktionsweise und Interaktion ist entscheidend, um Ausfälle zu minimieren, die Nutzerzufriedenheit zu maximieren und geschäftliche Prozesse zuverlässig zu halten.
So wird das Management von Retries zu einem zentralen Element moderner Softwareentwicklung und Systemarchitektur.