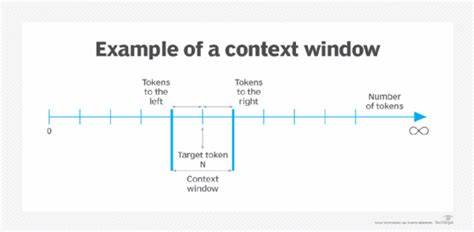
Im Zeitalter der Künstlichen Intelligenz (KI) und maschinellen Lernens stehen reasoning Agents, also KI-Systeme, die eigenständig Schlussfolgerungen ziehen, planen, erinnern und handeln, zunehmend im Mittelpunkt. Die Fähigkeit eines solchen Agents, komplexe Probleme zu lösen und sinnvolle Entscheidungen auf Grundlage umfangreicher Kontextinformationen zu treffen, hängt in hohem Maße von der Verarbeitung des sogenannten Kontextfensters ab. Doch mit der Ausweitung dieser Kontextfenster sind nicht nur Vorteile verbunden, sondern auch fundamentale Herausforderungen, die sich unter dem Begriff der Kontextfenster-Sättigung zusammenfassen lassen. Die Grundidee hinter der Kontextfenster-Erweiterung in neuronalen Netzwerken, insbesondere bei großen Sprachmodellen (LLMs), ist einfach: Je mehr Informationen ein Modell in einem einzigen Eingabezyklus verarbeiten kann, desto besser sollte theoretisch die Qualität und Präzision seiner Antworten sein. Unternehmen wie OpenAI oder Anthropic haben Modelle mit Kontextfenstern von Größenordnungen bis zu 200.
000 Tokens entwickelt, GPT-4.5 sogar mit bis zu 128.000 Tokens – weit über den traditionellen Grenzen von etwa 4.000 Tokens hinaus. Auf den ersten Blick scheint dies der Schlüssel zu komplexem, mehrstufigem Reasoning oder zur Analyse sehr großer Dokumente zu sein.
Doch die Realität ist differenzierter. Die Kontextfenster-Sättigung beschreibt das Phänomen, dass mit steigendem Umfang des Input-Kontextes die Fähigkeit eines KI-Systems, relevante Informationen effektiv zu extrahieren und zu verarbeiten, abnimmt. Dies führt häufig dazu, dass das System verstärkt fehlerhafte, redundante oder sogar halluzinierte Antworten generiert. Eine tiefergehende Untersuchung dieses Problems zeigt, dass die einfache Vergrößerung des Kontextfensters nicht zwangsläufig eine Verbesserung der reasoning Qualität nach sich zieht. Vielmehr sind komplexe Wechselwirkungen zwischen der Modellarchitektur, der Art der Eingabedaten und der internen Speicherverwaltung ausschlaggebend.
Ein zentraler Schwachpunkt ist die begrenzte Kapazität der zugrundeliegenden Transformermodelle. Diese architektonischen Komponenten verfügen über sogenannte Attention-Mechanismen, deren Rechen- und Speicheraufwand quadratisch mit der Länge der Eingabesequenz anwächst. Dadurch steigen die Kosten für Verarbeitung und Hardware-Ressourcen exponentiell an, was die praktische Nutzung extrem langer Kontextfenster limitiert. Gleichzeitig öffnen sich hier neue Fehlerquellen: Da das Modell nicht unendlich viel Kontext konsistent halten kann, entsteht vielfach sogenannter Kontextverlust oder Informationsüberschneidung, was die Präzision der Schlussfolgerungen schmälert. Darüber hinaus zeigen Untersuchungen, dass KI-Modelle bei sehr langen Kontexten dazu neigen, irrelevante oder doppelte Informationen zu berücksichtigen, was zu „overthinking“ führt – einem Zustand des übermäßigen Nachdenkens, der die Entscheidungsfindung erschwert.
Dies ähnelt menschlichem Verzetteln in komplexen Situationen und kann endlose Denkzyklen oder Abschweifungen nach sich ziehen. Ein weiteres Phänomen ist das sogenannte „Lost in the Middle“-Phänomen. Dabei erlangt der Inhalt am Anfang und am Ende des Kontextfensters die größte Aufmerksamkeit durch das Modell, während Informationen in der Mitte oftmals vernachlässigt werden. Für komplexe Dokumente oder Aufgaben mit vielschichtigen Informationen bedeutet dies potenziell das Auslassen zentraler Erkenntnisse. Besonders problematisch ist die „Nadel-im-Heuhaufen“-Situation, in der kritische, aber versteckte Informationen innerhalb der umfangreichen Kontextdaten schwer zugänglich bleiben.
In realen Anwendungsfällen, etwa bei der Analyse juristischer Dokumente, wissenschaftlicher Artikel oder umfangreicher Kundenfeedbacks, sind diese Schwächen deutlich spürbar. Die Qualität der reasoning Ergebnisse leidet erheblich, wenn relevante Fakten nicht erkannt oder falsch priorisiert werden. Vor diesem Hintergrund stellt sich die Frage, wie KI-Entwickler und Anwender mit diesen Limitierungen umgehen können. Eine offensichtliche Strategie ist ein bewusster Umgang mit dem Kontext und seinem Aufbau. Effektives Kontext-Engineering zielt darauf ab, die Menge der übermittelten Informationen nicht einfach zu maximieren, sondern intelligent zu gestalten.
Das bedeutet, Eingaben möglichst präzise und auf den Punkt zu bringen und redundante oder irrelevante Daten zu eliminieren. Wenn ein Agent beispielsweise ein langes Dokument analysiert, kann eine Vorverarbeitung durch Chunking sinnvoll sein – das Aufsplitten des Textes in sinnvolle Abschnitte, die einzeln abgerufen und verarbeitet werden. Medoid-Voting ist eine weitere innovative Methode, bei der aus einer größeren Menge von Textstücken repräsentative „Mediatoren“ ausgewählt und ihre Ergebnisse aggregiert werden. Dadurch erhöht sich die Robustheit gegenüber störenden Ausreißern und widersprüchlichen Datenfragmenten. Ebenso hilft das Erkennen von „Intracontext Interference“ – also dem gegenseitigen Stören verschiedener Informationsblöcke – die Effizienz der Informationen im Kontextfenster zu verbessern.
Technologisch kommen auch spezialisierte Architekturansätze zum Einsatz. Der Longformer etwa setzt auf ein Sliding-Window-Attention-Verfahren, das die Knotenpunkte der Aufmerksamkeit auf lokale Token-Beziehungen fokussiert und somit den Ressourcenbedarf erheblich reduziert. Dadurch ist es möglich, wesentlich längere Kontexte zu verarbeiten, ohne die Rechenkomplexität exponentiell steigen zu lassen. Diese Art der Anpassung ist entscheidend, um das Durchhaltevermögen von reasoning Agents bei großen Textmengen zu erhöhen. Zusätzlich gibt es ausgefeilte Methoden wie das „Activation Steering“, bei dem das Verhalten von Modellen durch gezielte Steuerung interner Aktivierungen beeinflusst wird.
Somit lässt sich die Richtung der Schlussfolgerungen effizienter kontrollieren, und das Modell wird von redundanten Denkpfaden abgehalten. Überthink-Detektion ist eine weitere wichtige Entwicklung, die erkennt, wenn Modelle im späten Prozessstadium frühere korrekte Reasoning-Ergebnisse verwässern oder überschreiben. Solche Kontrollmechanismen verhindern Fehlerketten und verbessern die Genauigkeit. Nicht zuletzt spielt das Management des Sitzungscaches oder des temporären Gedächtnisses eine wesentliche Rolle. Effektive Zwischenspeicherung der relevanten Informationen, strategisches Puffern und Bereinigen von Sessions erlauben es dem Agenten, mit den inhärenten Speicherbegrenzungen besser umzugehen und die für den momentanen Schritt relevanten Informationen auszuwählen.
Dieser gezielte Umgang mit Kurzzeit- und Langzeitspeicher ist fundamental für die Leistungsfähigkeit heutiger und zukünftiger reasoning Agents. Die Debatte um Kontextfenster-Sättigung reflektiert auch ein tieferes Verständnis der Natur von künstlicher Intelligenz: Sie zeigt, dass mehr Daten nicht automatisch zu besseren Ergebnissen führen. Stattdessen ist die Qualität, Struktur und das geschickte Management des Kontextmaterials entscheidend. Dieses Prinzip gilt sowohl für die Entwicklung neuer Algorithmen als auch für ihre praktische Anwendung in Bereichen wie Recht, Finanzen, Forschung und Kundenservice. Zusätzlich verdeutlicht die Problematik die Bedeutung eines differenzierten Benchmarkings.
Klassische deterministische Spiele wie das Tower of Hanoi, die durch algorithmisch festgelegte Lösungswege gekennzeichnet sind, bieten wenig Anhaltspunkte für den Umgang mit langem, komplexem Kontext. Dagegen eignen sich dynamische, unvorhersehbare Szenarien wie das Gefangenen-Dilemma oder mehrstufige Strategiespiele besser, um die realen Herausforderungen von reasoning Agents zu analysieren. Somit sollten Testumgebungen die Komplexität und Mehrdeutigkeit der echten Welt realistisch abbilden, um die Grenzen und Stärken von KI-Systemen valide zu erfassen. Insgesamt ist die Kontextfenster-Sättigung als Schlüsselthema für die Weiterentwicklung autonomer reasoning Agents zu verstehen. Die Forschung zeigt, dass wir lange Kontextfenster zwar technisch zunehmend realisieren können, dass aber die Effizienz und Effektivität dieser Modelle nur dann steigen, wenn begleitende Strategien zur Kontextoptimierung und zum intelligenten Gedächtnismanagement implementiert werden.
Die Kombination aus prompt-Optimization, semantischer Chunk-Aufteilung, spezialisierter Modellarchitektur und aktivem Steuerungsmechanismus wird zukünftig entscheidend sein, um die Versprechen großer Kontextfenster voll auszuschöpfen. Für Entwickler und Unternehmen bedeutet dies, dass ein erfolgreiches KI-Projekt weit über die Wahl eines leistungsfähigen Sprachmodells hinausgeht. Es bedarf sorgfältig konzipierter Eingabedaten, vorausschauender Prozessarchitekturen und eines tiefen Verständnisses für die spezifischen Grenzen und Fallstricke der aktuellen Technologie. Erst so lassen sich die Potenziale von KI-Agenten in Bereichen wie automatisierte Entscheidungsfindung, komplexe Analytik und strategische Planung voll entfalten. Abschließend lässt sich sagen, dass Kontextfenster-Sättigung kein reines technisches Detail ist, sondern eine fundamentale Schwachstelle, die direkt die Qualität von reasoning Agents beeinflusst.
Es liegt an der Community aus Forschern, Entwicklern und Anwendern, innovative Lösungsansätze zu finden und diese konsequent zu integrieren, um die nächste Generation intelligenter, effizenter und verlässlicher KI-Agenten zu schaffen.