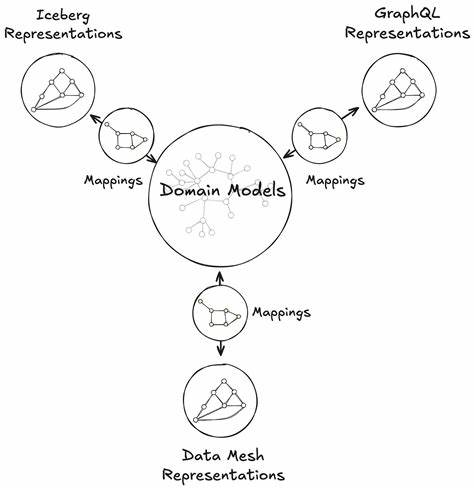
Die heutige Datenlandschaft bei großen Technologieunternehmen ist geprägt von enormen Mengen verschiedenartiger Daten, die aus unterschiedlichsten Quellen stammen. Netflix als einer der führenden Streaming-Dienste weltweit steht vor der Herausforderung, eine riesige Menge an Informationen aus Kundenverhalten, Content-Performance, Empfehlungen und betrieblicher Infrastruktur in Echtzeit auszuwerten und zu nutzen. Um diesem Anspruch gerecht zu werden, hat Netflix die Unified Data Architecture (UDA) eingeführt, die unter dem Motto "Model Once, Represent Everywhere" einen neuen Standard für datengetriebene Organisationen setzt. Die Grundidee der UDA ist, ein einziges, übergeordnetes Datenmodell zu schaffen, das alle Anforderungen der verschiedenen Anwendungsbereiche abdeckt. Dadurch entfällt die Notwendigkeit, mehrere isolierte Datenmodelle für einzelne Systeme oder Teams zu entwickeln und zu warten.
Dies sorgt nicht nur für eine höhere Konsistenz und Qualität der Daten, sondern ermöglicht auch eine schnellere Iteration und Innovation in der Datenanalyse und Nutzung. Traditionell berichteten Unternehmen oft mit einem Flickenteppich aus Datenbanken, Data Warehouses, Data Lakes und spezialisierten Streams, die jeweils eigene Modelle und Schnittstellen besaßen. Diese Diversität führte zu Inkonsistenzen, redundanter Datenverarbeitung, hohen Betriebskosten und zuletzt zu einer geringeren Agilität bei der Umsetzung neuer Anforderungen. Netflix erkannte, dass für die langfristige Skalierung und den Wettbewerbsvorteil eine harmonische Architektur essenziell ist, die die Datenintegrität wahrt und gleichzeitig Flexibilität bietet. Die Unified Data Architecture zeichnet sich dadurch aus, dass ein einzelnes Datenmodell definiert wird, das sämtliche Rohdaten in einen einheitlichen konzeptuellen Rahmen einbettet.
Dieses Modell spiegelt die Geschäftslogik und die Kernprozesse wider und bietet einen gemeinsamen Referenzpunkt für alle datenverarbeitenden Systeme. Von der Echtzeit-Datenverarbeitung über die Batch-Analyse bis hin zu Machine-Learning-Anwendungen nutzen alle Komponenten dasselbe zugrundeliegende Modell. Das bedeutet, dass Änderungen, Erweiterungen oder Korrekturen am Modell unmittelbar in allen Anwendungen wirksam werden, ohne dass Doppelarbeiten entstehen. Ein weiterer wesentlicher Aspekt ist die Möglichkeit, dieses Modell mit verschiedenen Darstellungsebenen ("Represent Everywhere") zu versehen. Das heißt, abhängig vom jeweiligen Use-Case können optimierte Sichten oder spezielle Datenrepräsentationen auf Basis des gemeinsamen Modells generiert werden, ohne die zugrundeliegenden Daten oder ihre Konsistenz zu gefährden.
Anwender in unterschiedlichen Abteilungen, sei es Marketing, Content-Management oder technische Teams, erhalten somit jeweils maßgeschneiderte Perspektiven, die ihren Anforderungen entsprechen, ohne unterschiedliche Datenquellen anzapfen zu müssen. Netflix verbindet mit der UDA nicht nur technische Innovation, sondern auch eine kulturelle Komponente. Die Architektur fördert die Zusammenarbeit und Transparenz zwischen Data Engineers, Analysten und Geschäftsbereichen. Alle Teams arbeiten mit einem gemeinsamen Vokabular und gemeinsamen Datenverständnis, was Missverständnisse und Inkonsistenzen minimiert. Darüber hinaus können Entwickler auf bewährte Bausteine und Schnittstellen zurückgreifen, was Entwicklungszyklen verkürzt und Innovation beschleunigt.
Technologisch basiert die UDA bei Netflix auf moderner Cloud-Infrastruktur und Big Data-Technologien wie Apache Kafka für Streaming-Daten, Apache Spark für Batch- und Stream-Processing und skalierbaren Data Lakes für die Speicherung. Die Architektur ist zudem darauf ausgelegt, skalierbar, ausfallsicher und hoch performant zu sein, um die Anforderungen von Millionen Nutzern und Milliarden Events täglich zu bewältigen. Der Einsatz von Machine Learning profitiert ebenfalls enorm von der UDA. Da Trainingsdaten, Feature-Sets und Modelloutputs auf demselben Modell und Datenschema basieren, können Algorithmen zuverlässiger und schneller trainiert und verbessert werden. Empfehlungen, Personalisierungen und dynamische Anpassungen der Content-Ausspielung profitieren so direkt von der sauberen, konsistenten Datenbasis.