In den letzten Jahren haben sich große Sprachmodelle (Large Language Models, LLMs) zu einer bahnbrechenden Technologie entwickelt, die mittlerweile in vielen Bereichen des Lebens und Wissenschaften eine entscheidende Rolle spielen. Besonders im Kontext der Chemie wirft die Leistungsfähigkeit dieser Modelle faszinierende Fragen auf: Wie gut können LLMs chemisches Wissen verstehen und anwenden? Können sie die Expertise erfahrener Chemiker ersetzen oder unterstützen? Welche Herausforderungen bestehen derzeit noch? Diese Fragestellungen berühren nicht nur die Grundlagenforschung, sondern beeinflussen auch Bildung, industrielle Anwendungen und Sicherheitsaspekte. Große Sprachmodelle basieren auf maschinellem Lernen und wurden mit enormen Mengen an Textdaten trainiert. Ihre Fähigkeit, menschenähnliche Sprache zu verstehen und zu generieren, schafft Grundlagen dafür, komplexe Fachfragen zu beantworten und sogar neue Ideen vorzuschlagen. Gerade im chemischen Kontext, wo ein Großteil des Wissens in Texten wie wissenschaftlichen Publikationen, Lehrbüchern und Datenbanken vorliegt, bieten LLMs ein enormes Potenzial.
Doch gilt das auch für Aufgaben, die tiefes Verständnis, kritisches Denken und chemisches Urteilsvermögen erfordern? Ein systematischer Vergleich von LLMs mit menschlicher Chemikerexpertise wurde möglich durch die Entwicklung spezieller Bewertungsrahmenwerke wie ChemBench. Diese Plattform enthält Tausende von Fragen aus verschiedensten Bereichen der Chemie, die sowohl reines Faktenwissen als auch komplexes logisches Nachdenken und experimentelles Verständnis abfragen. Die Auswertung von führenden Modellen, darunter proprietäre und Open-Source-Varianten, gegenüber Experten zeigt ein interessantes Bild: Die besten LLMs erreichen in vielen Fällen sogar eine bessere durchschnittliche Trefferquote als erfahrene Chemiker. Auf den ersten Blick klingt das nach einem Paradigmenwechsel. Sprachmodelle könnten künftig nicht nur bei Routinefragen helfen, sondern auch komplexe Problemstellungen lösen, bei denen der Zugang zu umfangreichen Textquellen und Datenbanken entscheidend ist.
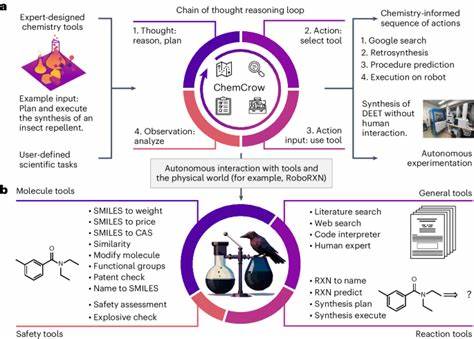
Dabei dürfen die Modelle sogar mit externen Werkzeugen kombiniert werden, etwa Suchmaschinen, Datenbankabfragen oder chemischen Strukturzeichnern. Solche multimodalen Systeme eröffnen ein neues Zeitalter chemischer Assistenzsysteme, die Forscher bei der Entwicklung von Molekülen, Syntheseplänen und Materialeigenschaften maßgeblich unterstützen. Allerdings offenbarten die Untersuchungen von ChemBench auch wesentliche Einschränkungen. Die Modelle sind teilweise unsicher, liefern übermäßig selbstbewusste, aber falsche Antworten oder scheitern bei Aufgaben, die tiefgreifende chemische Argumentation erfordern, etwa bei der Analyse von spektralen Daten oder detaillierten Reaktionsmechanismen. Besonderes Defizit zeigen die Sprachmodelle bei der Einschätzung von chemischer Sicherheit und Toxizität.
Diese Felder sind für den Schutz von Forschern und Umwelt essenziell, wodurch eine volle Verlässlichkeit der Systeme unabdingbar ist. Einen weiteren kritischen Punkt stellt die mangelnde Fähigkeit der Modelle dar, ihre eigene Sicherheit einzuschätzen. In Tests zeigten LLMs kaum eine zuverlässige Korrelation zwischen der eigenen Einschätzung der Antwortsicherheit und der tatsächlichen Richtigkeit. Diese Über- oder Fehleinschätzung kann im professionellen Kontext fatale Folgen haben, da Anwender nicht immer Experten sind und Modelle in falscher Sicherheit wiegen könnten. Die Diskrepanz zwischen beeindruckender Breite und beschränkter Tiefe des chemischen Wissens der LLMs aufdeckt zugleich neue Anforderungen an die Chemieausbildung.
Klassisches Lernen vor allem auf der Basis von reiner Wissenswiedergabe verliert an Stellenwert, wenn Maschinen in der Faktenwiedergabe überlegen sind. Kritisches Denken, Methodik, Experimentierkompetenz und die Fähigkeit, Informationen zu hinterfragen, rücken stärker in den Vordergrund. Lehrpläne könnten sich daher wandeln, um die Synergien zwischen menschlichem Know-how und KI besser zu nutzen. Darüber hinaus offenbart die Variabilität der Modellleistung über unterschiedliche Fachgebiete die Notwendigkeit spezialisierter Ansätze. Modelle zeigen relativ gute Ergebnisse bei allgemeiner und technischer Chemie, aber etwa bei analytischer Chemie oder chemischem Sicherheitswissen schwanken die Trefferquoten stark.
Es bedarf also einer Weiterentwicklung hin zu domänenspezifisch trainierten und durch spezialisierte Datenbanken ergänzten Modellen. Ein weiterer spannender Forschungszweig beschäftigt sich mit der Modellierung von chemischer Intuition, also der Fähigkeit von Chemikern, anhand abstrakter Kriterien Stoffe zu bevorzugen oder zu optimieren. Erste Tests zeigen, dass LLMs bei diesen subjektiven, oft emotional gefärbten Entscheidungen bisher kaum mit menschlicher Expertise mithalten können. Hier könnten fortschrittliche Trainingsmethoden mit Präferenzlernen in Zukunft neue Perspektiven eröffnen. Auch ethische Überlegungen und Sicherheitsaspekte spielen eine wichtige Rolle.
Die duale Nutzbarkeit der Technologie – etwa für die Entwicklung von nützlichen Medikamenten oder potenziell gefährlichen Stoffen – verlangt einen verantwortungsvollen Umgang, der Transparenz und Prüfung sicherstellt. Angesichts des breiten Nutzerkreises, der von Studierenden bis zu Laien reicht, muss sichergestellt werden, dass die Modelle keine irreführenden oder gefährlichen Fehlinformationen verbreiten. Zusammenfassend lässt sich sagen, dass große Sprachmodelle die Chemiebranche bereits heute nachhaltig verändern. Sie bringen beeindruckende Leistungen bei der Wissensverarbeitung und unterstützen wissenschaftliche Arbeit auf neue Weise, stehen jedoch vor Herausforderungen in Bezug auf Sicherheit, Präzision und tiefgehendes Verständnis. Ein ausgewogenes Zusammenspiel von menschlicher Expertise und maschineller Assistance wird die Zukunft der chemischen Forschung und Ausbildung prägen.
Um den Fortschritt gezielt voranzutreiben, sind neue standardisierte Benchmark-Systeme für die chemische Domäne unerlässlich, wie es ChemBench eindrucksvoll demonstriert. Solche Bewertungsinstrumente helfen, Stärken und Schwächen differenziert zu erfassen, den qualitativen Sprung zu realisieren und zugleich Risiken frühzeitig zu erkennen. Zudem eröffnen die Erkenntnisse der Evaluierungen Perspektiven für die Entwicklung besserer Mensch-Maschine-Kooperationen. Die Integration von LLMs als Copiloten im Labor, die intuitive Bedienbarkeit von Systemen und vor allem die Kommunikation von Unsicherheiten werden entscheidend sein, um Vertrauen zu schaffen. Langfristig könnte die Verbindung von KI mit experimentellen Automatisierungssystemen die chemische Forschung revolutionieren.
Roboter, gesteuert durch präzise formulierte natürliche Sprache, können eigenständig experimentieren, Daten analysieren und Hypothesen generieren. Trotz der überzeugenden Fortschritte bleibt der Mensch als kritisch reflektierender Forscher zentral. Die Zukunft der Chemie ist zweifelsohne stark von der Sprache geprägt – nicht nur durch das geschriebene Wort, sondern durch die maschinelle Verarbeitung dessen. Große Sprachmodelle eröffnen ganz neue Wege des Zugangs zu Wissen und Kompetenz. Doch ihre besten Ergebnisse entstehen in der Kombination mit menschlicher Intuition, Erfahrung und ethischer Verantwortung.
Die gemeinsamen Anstrengungen von Chemikern, Informatikern und Pädagogen werden maßgeblich darüber entscheiden, wie diese Technologien gestaltet und eingesetzt werden, damit sie sowohl Innovation fördern als auch Sicherheit gewährleisten. Insgesamt zeigt sich also ein faszinierendes Bild: Große Sprachmodelle sind angekommen in der Welt der Chemie. Ihre Möglichkeiten sind groß, ihre Grenzen offen und der Weg zu ihrer optimalen Nutzung spannend. Für Forscher, Studierende und die Industrie bietet dies die Chance, schneller, klüger und sicherer zu agieren – mit Hilfe intelligenter Systeme, die Sprache verstehen und Chemie neu denken.