Die rasante Entwicklung von Großsprachmodellen (Large Language Models, LLMs) hat in den letzten Jahren viele Bereiche der Wissenschaft und Technologie grundlegend verändert. Besonders in der Chemie zeigen diese KI-gestützten Systeme eine immer größere Fähigkeit, komplexe Aufgaben zu bearbeiten, die zuvor ausschließlich menschlichen Experten vorbehalten waren. Dabei reichen die Anwendungen von der Beantwortung vielschichtiger chemischer Fragen über die Vorhersage von Moleküleigenschaften bis hin zur Unterstützung bei der Planung von Synthesen. Doch wie verhalten sich diese Technologien im direkten Vergleich zum Know-how erfahrener Chemiker? Welche Stärken und Schwächen zeigen sich, und welche Konsequenzen ergeben sich daraus für Forschung, Lehre und Sicherheit? Diese Fragestellungen stehen im Zentrum aktueller Untersuchungen, die den Einsatz von LLMs in der Chemie systematisch evaluieren und mit menschlicher Expertise gegenüberstellen. Großsprachmodelle verstehen und verarbeiten natürliche Sprache, wodurch sie in der Lage sind, auf eine Vielzahl von Fragen zu antworten, auch wenn sie zu diesen Themen nicht explizit trainiert wurden.
Die Dimensionen ihrer Fähigkeiten bewegen sich heute oft auf einem Niveau, das professionelle Prüfungen, wie etwa in der Medizin, bereits übertrifft. Die Chemie stellt dabei ein besonders anspruchsvolles Einsatzgebiet dar, da Fachwissen und logisches Denken auf mehreren Ebenen erforderlich sind – von der Kenntnis molekularer Strukturen und Reaktionsmechanismen über die Interpretation experimenteller Daten bis zur Einschätzung von Sicherheitsaspekten. Eine innovative Benchmarking-Plattform namens ChemBench wurde entwickelt, um diese komplexen Fähigkeiten von LLMs systematisch zu messen. Die Plattform umfasst eine umfangreiche Sammlung von mehr als 2.700 Frage-Antwort-Paaren, die unterschiedliche Kompetenzbereiche in der Chemie abdecken.
Dabei variieren die Fragen stark hinsichtlich Themengebiet, Schwierigkeitsgrad und den erforderlichen kognitiven Fähigkeiten – von reinem Faktenwissen über Rechenaufgaben bis hin zu anspruchsvollen logischen Schlussfolgerungen und chemischer Intuition. Der Vergleich von LLMs mit menschlichen Chemikern auf Basis von ChemBench zeigt bemerkenswerte Ergebnisse: Spitzenmodelle erreichen eine durchschnittliche Leistungsfähigkeit, die über der besten menschlichen Expertise liegt. Dieses Resultat verdeutlicht, dass die KI inzwischen nicht nur einfache Fakten abrufen, sondern auch komplexe Probleme mit beachtlicher Genauigkeit lösen kann. Trotz dieser Erfolge zeigt sich jedoch auch, dass die Modelle bei bestimmten grundlegenden Aufgaben Schwächen aufweisen und zu selbstsicheren, aber falschen Antworten neigen. Eine zuverlässige Einschätzung der eigenen Sicherheit bei Antworten scheint für viele Modelle noch eine Herausforderung zu sein, was potenzielle Risiken beim Einsatz bringt.
Die Leistung der LLMs ist zudem stark abhängig von ihrem Trainingsumfang und ihrer Architektur. Generell korreliert eine Zunahme der Modellgröße mit besseren Ergebnissen, was auch auf Chemie-Modelle zutrifft. Gleichzeitig wird deutlich, dass das Training auf spezialisierten Datenbanken, etwa zur Toxizität oder zu Moleküleigenschaften, noch deutlich verbessert werden kann. Einige Aufgaben verlangen Wissen, das über wissenschaftliche Publikationen hinausgeht und spezielles Fachwissen aus zertifizierten Datenbanken erfordert. Hier liegen für die Weiterentwicklung von chemischen Sprachmodellen große Chancen, indem diese mit besseren und umfangreicheren Quellen verbunden werden.
Bei der Betrachtung verschiedener Themengebiete wird sichtbar, dass sowohl Menschen als auch Maschinen in bestimmten Problemfeldern unterschiedlich gut abschneiden. Während allgemeine und technische Chemie von vielen Modellen gut bewältigt werden, sind Sicherheitsthemen oder analytische Chemie komplexer und führen zu niedrigeren Erfolgsraten. Die Vorhersage der Anzahl von Signalen in Kernspinresonanzspektroskopien etwa ist eine anspruchsvolle Aufgabe, die selbst den besten Modellen Schwierigkeiten bereitet. Dies liegt unter anderem daran, dass für solche Probleme nicht nur Rechenleistung, sondern ein tiefes Verständnis molekularer Symmetrien und Strukturen erforderlich ist – Aspekte, bei denen LLMs bisher nur eingeschränkt „reasonieren“ können. Ein weiterer interessanter Befund betrifft die Fähigkeit der Modelle, menschliche Präferenzen in der Chemie zu beurteilen, zum Beispiel im Kontext der Wirkstoffentwicklung.
Im Gegensatz zur Expertenmeinung gelingt es den meisten LLMs derzeit nicht, die komplexe Intuition und das Gefühl für „interessante“ Moleküle überzeugend nachzuvollziehen. Dies zeigt, dass das Training auf rein datengetriebenen Informationen die subtilen Aspekte der Chemikerodisse noch nicht vollständig abbilden kann. Die Integration von Präferenzlernen und besserer Modellierung menschlicher Entscheidungsprozesse wird hier als ein zukunftsträchtiger Ansatz angesehen. Neben den reinen Leistungsparametern ist auch die Sicherheit bei der Nutzung dieser Technologien von großer Bedeutung. LLMs können, vor allem bei nicht optimaler Datengrundlage oder fehlendem Kontext, Fehlinformationen generieren – was in sensiblen Bereichen wie der Chemie gefährliche Konsequenzen haben kann.
Die mangelnde Fähigkeit einiger Modelle, ihre Unsicherheit zuverlässig zu erkennen und zu kommunizieren, verstärkt dieses Risiko. In der Praxis ist es deshalb entscheidend, dass Nutzer die Limitationen der KI kennen und dass Modelle so gestaltet werden, dass sie ihre Risiken angemessen einschätzen und transparent machen können. Die Einführung von LLMs in die chemische Forschung und Lehre wirft auch pädagogische Fragen auf. Wenn Algorithmen zunehmend Routineaufgaben übernehmen und Faktenwissen verknüpfen können, muss sich die Ausbildung von Chemikern stärker auf kritisches Denken, komplexe Problemlösung und experimentelles Design konzentrieren. Die traditionellen Prüfungsformate verlieren durch die Möglichkeit, Lösungen durch KI zu erhalten, ihre Wirksamkeit als alleiniger Maßstab.
Stattdessen rücken Verständnis, kreative Anwendung und die Fähigkeit zur Bewertung der Antwortqualität mehr in den Vordergrund. Das Potenzial von LLMs als „Chemie-Kopiloten“ ist beachtlich. Sie könnten Zukunftsforschung beschleunigen, indem sie große Mengen an Literatur und Datensätzen schnell durchforsten, neue Hypothesen generieren und experimentelle Designs vorschlagen, die das Wissen einzelner Forscher übersteigen. Dabei ist jedoch klar, dass Menschen weiterhin unverzichtbar bleiben – sowohl für die Bewertung der Ergebnisse als auch für die Interpretation und Durchführung von Experimenten. Ein besonderer Vorteil von LLMs ist ihre Fähigkeit, Sprache als zentrale Informationsquelle der Chemie zu erschließen.
Da das meiste Wissen in der Chemie in Textform gespeichert ist, zum Beispiel in wissenschaftlichen Publikationen, Patenten und Lehrmaterialien, eröffnen sich durch Sprachmodelle neue Wege, um Erkenntnisse automatisiert zu extrahieren und zu verknüpfen. Dies kann zu einer verbesserten Wissensbasis führen, die menschliche Kapazitäten ergänzt und erweitert. Trotz aller Fortschritte zeigen die Untersuchungen auch, dass die derzeitigen Modelle bei spezifischen chemischen Fragestellungen weiterhin limitiert sind. Viele Antworten basieren auf dem, was sie in Trainingsdaten gesehen haben, manchmal ohne echtes Verständnis der zugrunde liegenden Prinzipien – eine Herausforderung, die in der Forschung als Problem der „stochastischen Papageien“ diskutiert wird. Das heißt, die Modelle imitieren das Gesehene, ohne neues Wissen kreativ zu generieren oder tiefgründe Zusammenhänge zu erfassen.
Daher empfehlen Experten, weiterhin an der Entwicklung gezielter Benchmarks wie ChemBench zu arbeiten, um Fortschritte messbar zu machen und Risiken zu minimieren. Eine offene Zusammenarbeit zwischen Chemikern, KI-Forschenden und Industrie ist notwendig, um Systeme zu schaffen, die sicher, robust und praxisrelevant sind. Ein weiterer Punkt ist die Dual-Use-Problematik. Die leistungsfähigen Modelle können sowohl für nützliche Zwecke, wie die Entwicklung ungiftiger Substanzen, als auch für schädliche Anwendungen, etwa zur Konzeption gefährlicher Chemikalien, genutzt werden. Die Kontrolle und Regulierung des Zugangs zu solchen Systemen ist daher ein wichtiges gesellschaftliches Thema.
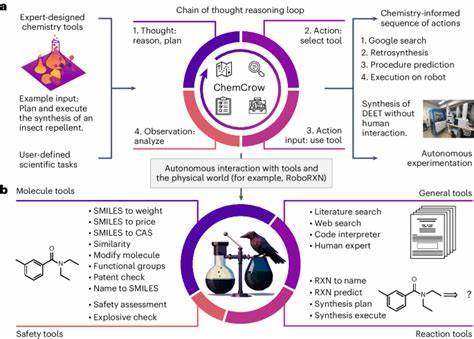
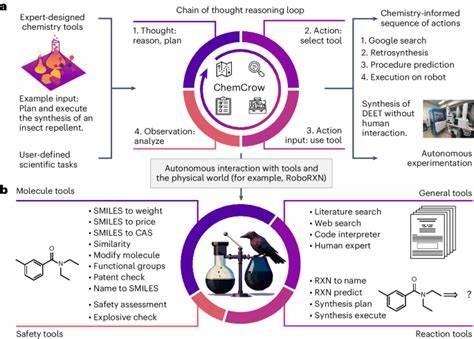
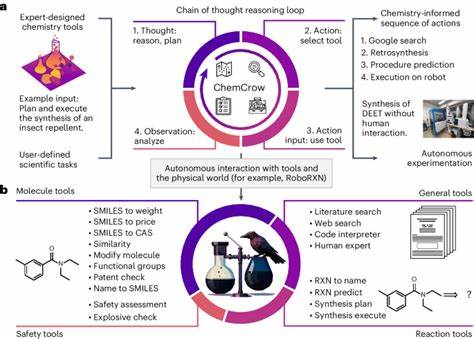
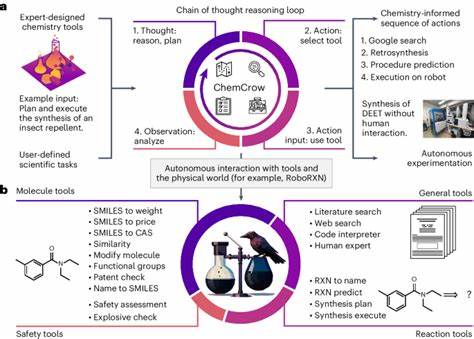
Auf der technischen Seite stellt sich die Frage, wie LLMs in Verbindung mit externen Werkzeugen noch effizienter werden können. Das Einbinden von spezialisierten Datenbanken und Rechenwerkzeugen, zum Beispiel für Molekülvisualisierung oder Reaktionssimulation, könnte die Grenzen der Sprachmodelle erweitern und eine noch präzisere Unterstützung bieten. Agentenartige Systeme, die verschiedene Module und Quellen intelligent kombinieren, werden als ein vielversprechender Weg gesehen. Zusammenfassend zeigen die aktuellen Studien, dass Großsprachmodelle die chemische Expertise in zahlreichen Bereichen nicht nur erweitern, sondern teilweise übertreffen können. Dies erfordert ein Umdenken in der Ausbildung, Forschung und im Umgang mit chemischem Wissen.