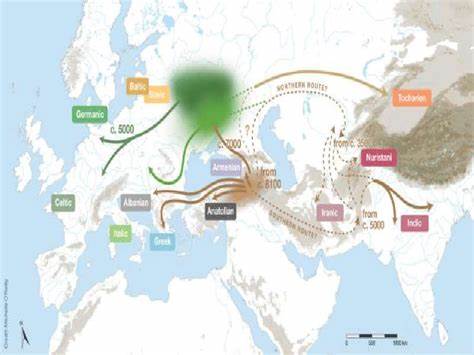
Die Indogermanische Sprachfamilie, zu der Sprachen wie Deutsch, Englisch, Sanskrit und viele andere gehören, zählt zu den am intensivsten erforschten Sprachgruppen der Welt. Seit Jahrzehnten beschäftigen sich Linguisten mit der Frage nach ihrem Ursprung – speziell wie und wo sich Proto-Indogermanisch entwickelt hat und ob die Entstehung auf eine einzige Region oder auf eine komplexere, hybride Entwicklung zurückzuführen ist. In den vergangenen Jahren haben moderne computergestützte Methoden, insbesondere phylogenetische Analysen, neue Impulse in diesem Forschungsfeld geliefert. Eine besonders interessante Methode verwendet sogenannte Sprachbäume mit „sampled ancestors“ – also Stammesvorfahren, die in die Aufstellung der Sprachstammbäume direkt einbezogen werden. Doch unterstützen diese Modelle tatsächlich einen hybriden Ursprung der indogermanischen Sprachen oder werfen sie lediglich neue Fragen auf? Phylogenetische Sprachbäume sind eine Methode, bei der die sprachliche Verwandtschaft mithilfe von Algorithmen, die ähnlich wie bei biologischen Stammbäumen funktionieren, rekonstruiert wird.
Dabei werden Wortlisten, Lautentwicklungen, Grammatik und weitere linguistische Merkmale analysiert, um Beziehungen abzuleiten. Der Clou bei Modellen mit sampled ancestors ist, dass neben den heutigen und historischen Sprachen auch Zwischenschritte und mögliche Vorfahr-Sprachstufen berücksichtigt werden. So können Forscher versuchen, die Entwicklungsschritte zwischen alten und modernen Sprachen detaillierter abzubilden. Insbesondere das jüngst von Heggarty, Anderson und Kollegen 2023 veröffentlichte Modell bewirbt sich als umfassendste Analyse von Grundvokabular und Sprachgeschichte, die bisher durchgeführt wurde. Die Studie stützt sich auf eine umfangreiche Datenbank namens IE-CoR, die Grundwortschatzlisten von 161 indogermanischen Sprachvarianten und Dialekten umfasst.
Dabei wurde streng auf die Qualität der lexikalischen Daten geachtet, was gegenüber früheren Arbeiten der Forschung um Gray und Atkinson eine deutliche Verbesserung bedeutet. Die Daten wurden mit Hilfe von vier Jahren Arbeit eines internationalen Forscherteams, darunter prominente Spezialisten verschiedener indogermanischer Zweige, sorgfältig zusammengestellt. Dennoch weist die kritische Analyse von Kassian und Starostin im Jahr 2025 gravierende methodische und interpretative Probleme auf, die die Zuverlässigkeit der Ergebnisse in Frage stellen. Zu den Problemen gehört die Schwierigkeit, echte genetische Verwandtschaft von sprachlichen Ähnlichkeiten, die durch Kontakt und Lehnwörter entstanden sind, zu unterscheiden. Ein weiteres Thema ist die „derivational drift“, bei der ähnliche Wörter in verschiedenen Sprachen zwar dieselbe Wurzel haben, sich aber unabhängig voneinander semantisch und morphologisch weiterentwickelt haben, wodurch eine falsche Verwandtschaft suggeriert werden kann.
Solche Faktoren verzerren die Darstellung in phylogenetischen Bäumen, da sie als vererbt interpretiert werden, obwohl sie eigentlich Produkt von Sprachkontakt oder parallel verlaufenden Entwicklungen sind. Darüber hinaus verweist die Kritik darauf, dass die Datengrundlage mit 170 Konzepten zwar umfangreich erscheint, aber für 161 Sprachvarianten nicht ausreicht, um ein robustes Klassifizierungsergebnis zu erzielen. Die Anzahl der verglichenen Merkmale sollte proportional zur Zahl der Sprachbelege wachsen, sonst entstehen statistische Unsicherheiten und instabile Baumstrukturen. Durch den Versuch, möglichst viele Klänge und Wortlisten unterzubringen, werden Inkonsistenzen und Fehler womöglich erst verstärkt. Kassian und Starostin schlagen daher eine eher reduktionistische Herangehensweise vor, bei der weniger Sprachvarianten, dafür aber genauer rekonstruierte Zwischenstufen als Charaktere genutzt werden, um die evolutionären Prozesse besser abbilden zu können.
Die Frage nach der Herkunft der indogermanischen Sprecher ist ein weiterer Streitpunkt. Die etablierte „Steppe-Hypothese“ geht von der einheitlichen Herkunft aus der Pontisch-kaspischen Steppe aus, während die „Anatolien-Hypothese“ eine Herkunft aus dem anatolischen Raum im Frühneolithikum favorisiert. Heggarty et al. wollen mit ihrem hybriden Modell beide Sichtweisen miteinander verbinden und zeigen, dass die Indo-Anatolischen Sprachen früh abzuzweigen scheinen, doch die nachfolgenden Entwicklungen angefangen im Steppengebiet stattfinden könnten. Doch steht die Datierung der Trennungszeitpunkte und die dabei erstellte Baumstruktur, besonders in der vorgeschlagenen Reihenfolge der Entstehung der Untergruppen, im Widerspruch zu gut belegtem historischen und archäologischen Wissen.
Die Schlüssel-Äste des Baumes etwa vereinen ungewöhnlich Hethitisch und Tocharisch, was von Experten als unplausibel bewertet wird. Eine weitere Kritik betrifft die Veröffentlichung und Darstellung der Ergebnisse. Statt klarer Bäume werden häufig „Maximum Clade Credibility“ (MCC)-Bäume präsentiert, die zwar den höchstwahrscheinlichen Baum zeigen, aber auch mit vielen Unsicherheiten behaftet sind. Eine robustere Darstellung ist der „Majority Rule Consensus“ (MRC)-Baum, bei dem nur Zweige berücksichtigt werden, die in mindestens 50% der Modelle auftauchen und weniger sichere Verzweigungen als Mehrfachverzweigung (Polytomie) gelten, was bei Sprachentwicklung oft realistischer ist. Nur durch diesen Schritt lässt sich klar erkennen, welche Knotenpunkte gut gestützt und welche eher spekulativ sind.
Insgesamt zeigt die Analyse, dass Sprachbäume mit sampled ancestors zwar einen spannenden Ansatz in der Komplexitätsreduktion bieten, aber noch mit erheblichen methodischen Herausforderungen zu kämpfen haben. Insbesondere die Gefahr, dass Resultate von computationalen Modellen voreilig als endgültige Beweise interpretiert werden und im Widerspruch zur traditionellen historischen Sprachwissenschaft stehen, ist groß. Für viele Fachleute bleibt daher der alte Ansatz der sorgfältigen vergleichenden Analyse mit linguistischen und archäologischen Daten unverzichtbar. Die Verwendung großer Datensätze und komplexer Bayesianischer Modelle stellt ein vielversprechendes Instrument dar, birgt jedoch die Gefahr, dass Fehler in der Datenannotation, fehlerhafte semantische Zuordnung oder inkorrekte Behandlung von Lehnwörtern die ganze Analyse verzerren können. Die Berücksichtigung von Sprachwandel durch Kontakt, Arealbildung und sprachliche Homoplasie bleibt eine Herausforderung, die durch rein computergestützte Verfahren allein nicht gelöst werden kann.
Damit lässt sich zusammenfassend sagen, dass die neuesten Sprachbaum-Modelle mit sampled ancestors keinen klaren Beleg für ein hybrides Entstehungsmodell der indogermanischen Sprache liefern. Vielmehr zeigen sie, dass das Modell eines einfachen baumartigen Stammbaums der Sprachfamilie nicht ohne weiteres aufrechterhalten werden kann und dass komplexe Interaktionen zwischen Sprachgruppen und Sprachkontakt eine stärkere Rolle spielen. Allerdings bleiben die Resultate aufgrund daten- und methodenbedingter Einschränkungen in ihrer Aussagekraft begrenzt und sollten mit Vorsicht interpretiert werden. In der Zukunft könnten weiter optimierte Datenbanken und die Integration anderer methodischer Ansätze, beispielsweise etymologischer Plausibilitätsprüfungen, sowie interdisziplinäre Zusammenarbeit mit Archäologen und Anthropologen dazu beitragen, ein umfassenderes und realistischeres Bild vom Ursprung und der Ausbreitung der indogermanischen Sprachen zu zeichnen. Der Brückenschlag zwischen computergestützter Phylogenetik und klassischer vergleichender Sprachwissenschaft bleibt dabei eine wichtige Aufgabe.
Letztlich illustriert die Debatte um Sprachbäume mit sampled ancestors sehr gut, wie schwierig die Rekonstruktion großer, komplexer Sprachfamilien ist. Während moderne Technologien neue Möglichkeiten eröffnen, bleibt das sorgfältige Linguistik-Handwerk und die kritische Reflexion über Datenqualität und verwendete Methoden unverzichtbar, um verlässliche Erkenntnisse über die Herkunft der faszinierenden Indogermanischen Sprachfamilie zu gewinnen.




![ChatGPT controlled turtle graphics in Emacs [video]](/images/6EF6AEA9-AF51-4D94-8DC1-13735AF8AB30)