Die rasante Entwicklung im Bereich der Künstlichen Intelligenz (KI) hat die Anforderungen an Rechenleistung und Effizienz enorm gesteigert. CUDA, als leistungsfähige Programmierschnittstelle von NVIDIA, ermöglicht die parallele Nutzung von Grafikprozessoren (GPUs) für komplexe Berechnungen, die insbesondere bei Deep Learning Modellen unverzichtbar geworden sind. Dabei ist es längst nicht mehr nur die schiere Rechenkapazität der GPU, die über die Performance entscheidet, sondern vor allem die Art und Weise, wie mit dem begrenzten Speicher umgegangen wird. Speicheroptimierung hat sich als der entscheidende Faktor erwiesen, um hochperformante CUDA-Kernels zu schreiben, die KI-Anwendungen effizient skalieren lassen. Die tensorbasierten Recheneinheiten, wie Tensor Cores, sind in modernen GPUs extrem schnell und leistungsfähig geworden.
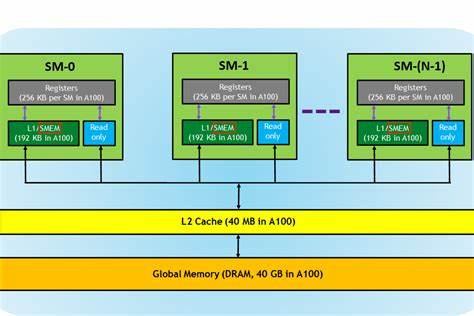
Dennoch werden sie häufig durch langsame oder ineffiziente Speicherzugriffe ausgebremst. Die Speicherbandbreite und -latenz stellen oft den Engpass dar, wodurch das volle Potenzial der Compute Units nicht ausgeschöpft wird. Für Entwickler von CUDA-Kernels bedeutet dies, dass der Fokus immer stärker auf das effektive Laden, Speichern und Verwalten von Daten gelegt werden muss, um die Einheiten konstant mit Informationen zu versorgen und so Wartezeiten durch Speicherkonflikte oder unnötige Transfers zu vermeiden. Ein zentraler Aspekt der Speicheroptimierung ist das Verständnis der verschiedenen Speicherhierarchien innerhalb der GPU. Während Register den schnellsten Zugriff bieten, sind sie in der Kapazität sehr begrenzt.
Shared Memory, der ebenfalls sehr schnell ist, bietet viel Raum für die gemeinsame Datennutzung innerhalb eines Blocks. Im Gegensatz dazu ist globaler Speicher sehr umfangreich, aber deutlich langsamer. Effiziente CUDA-Kernels minimieren den Zugriff auf globalen Speicher und maximieren die Nutzung von Register und Shared Memory. Hierfür sind Techniken wie das sogenannte Memory Coalescing unerlässlich. Dabei werden Speicherzugriffe so organisiert, dass benachbarte Threads auch benachbarte Speicherbereiche lesen oder schreiben, was die Speicherbandbreite erheblich erhöht.
Zusätzlich hilft die Nutzung von Lese-Caches oder Read-Only Data Caches, um die Auslastung des globalen Speichers zu optimieren. Die Herausforderung beim Schreiben von CUDA-Kernels für Deep Learning besteht insbesondere darin, die Datenströme so zu steuern, dass die Tensor Cores stets optimal versorgt sind. Da diese Einheiten exponentiell mehr Rechenoperationen pro Takt bieten, werden sie schnell zum Flaschenhals, wenn Daten nicht schnell genug bereitgestellt werden. Entwickler müssen daher neben der Kernel-Logik auch die Speicherzugriffsarchitektur genau analysieren und optimieren. Neben dem technischen Umgang mit Speicherhardware spielen auch algorithmische Anpassungen eine wichtige Rolle.
Beispielsweise wird durch das Reorganisieren von Daten oder das Reduzieren unnötiger Datenbewegungen die Gesamtperformance messbar gesteigert. Ein weiterer Aspekt ist die Nutzung von Synchronisationsmechanismen innerhalb der GPU, um die Datenkonsistenz bei gleichzeitigen Zugriffen zu gewährleisten. Hier kommen Atomics ins Spiel. Atomare Operationen sind essenziell, wenn mehrere Threads gleichzeitig auf dieselben Speicherbereiche zugreifen müssen, ohne Inkonsistenzen zu verursachen. Obwohl Atomics oft mit einem Performance-Overhead verbunden sind, können sie in Deep Learning Anwendungen durchaus sinnvoll eingesetzt werden, insbesondere bei der Aggregation von Gradienten oder Updates während des Trainings.
Der richtige Einsatz von atomaren Operationen erfordert jedoch ein tiefgehendes Verständnis der zugrundeliegenden Hardware und Programmiermodelle sowie sorgfältige Planung, um Hotspots und Synchronisationsprobleme zu vermeiden. Die regelmäßige Profilierung und Analyse von CUDA-Kernels ist ebenfalls unverzichtbar zur Erkennung von Speicherengpässen und Leistungsbremsen. Tools wie NVIDIA Nsight oder nvprof erlauben eine detaillierte Einsicht in Speicherzugriffsmuster, Latenzen und Bandbreitenauslastung und helfen Entwicklern, gezielt Optimierungen vorzunehmen. Ein weiterer Trend ist die Verwendung von Mixed Precision Berechnungen in Kombination mit optimierten Speicherzugriffen. Mixed Precision ermöglicht eine schnellere Verarbeitung durch geringere Datenmengen, was die Speicherbandbreite und Cache-Auslastung entlastet und somit die Tensor Cores effizienter voranbringt.
Abschließend lässt sich sagen, dass die Speicheroptimierung das Herzstück bei der Entwicklung von CUDA-Kernels für KI-Anwendungen bildet. Die schiere Rechenleistung moderner Tensor Cores ist nur dann von Vorteil, wenn die Daten in der richtigen Form, zum richtigen Zeitpunkt und mit minimalen Verzögerungen bereitgestellt werden. Wer als Entwickler die Kunst beherrscht, Speicherzugriffe präzise zu planen, geeignete Synchronisationsmechanismen einzusetzen und die Speicherhierarchie effizient auszunutzen, wird hochperformante und skalierbare CUDA-Kernels schreiben können, die den Anforderungen moderner KI-Workloads gerecht werden. Die Zukunft der GPU-basierten KI-Beschleunigung liegt maßgeblich darin, Speicher- und Datenmanagement zu meistern und so die Balance zwischen Rechenleistung und Speicherzugriffen optimal zu gestalten.