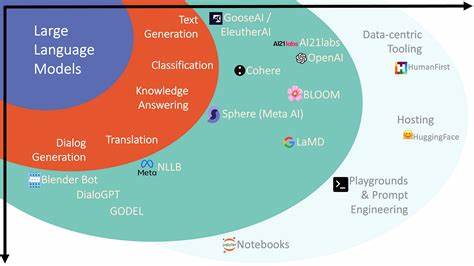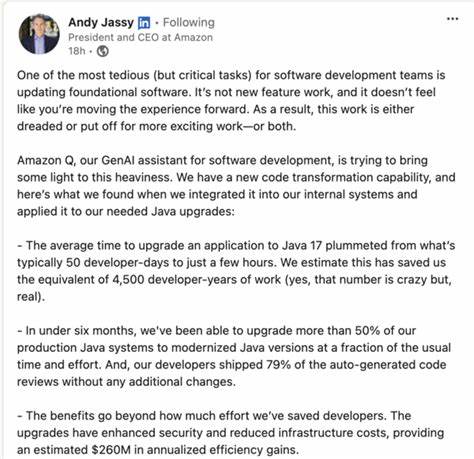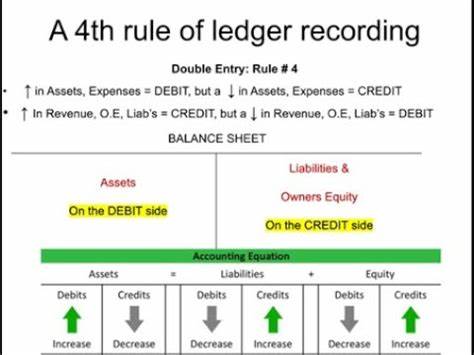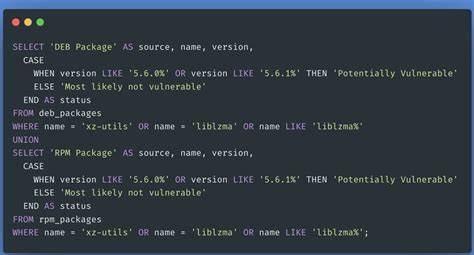
In der Softwareentwicklung sind „Utils“ (Utilities) allgegenwärtig. Sie dienen als Sammelstelle für verschiedene Hilfsfunktionen, die häufig über ein Projekt hinweg wiederverwendet werden. Auf den ersten Blick scheint dies eine clevere Methode zu sein, um Code logisch zu gruppieren, die Wiederverwendbarkeit zu fördern und den Überblick zu behalten. Doch bei näherem Hinsehen offenbaren sich in der Praxis erhebliche Nachteile, die den Entwickler früher oder später vor große Herausforderungen stellen können. Ein Beispiel aus der täglichen Programmierpraxis hilft, diese Problematik besser zu verstehen.
Im Kern bestehen Utils aus einfachen Funktionen oder Klassen, die keine direkte Domänenlogik darstellen, sondern Hilfsaufgaben übernehmen. Es gibt Payment-Utils, Email-Utils, User-Utils und viele mehr. Das Ziel ist klar: Ähnliche Funktionen werden an einem Ort gebündelt, sodass Entwickler gezielt die passenden Utils importieren können, wenn sie bestimmte Aufgaben erledigen wollen. Auf der Oberfläche erscheint dieses Muster sinnvoll und intuitiv. Die Komplexität beginnt, sobald Funktionen aus verschiedenen Utils sich gegenseitig benötigen.
Ein typisches Beispiel wäre eine Funktion, die eine Zahlung verarbeitet und automatisch eine Bestätigungs-E-Mail versendet. Wo gehört diese Funktion hin? Ist sie Teil der Payment-Utils, weil sie zur Zahlungsabwicklung gehört? Oder in die Email-Utils, weil es sich um den Versand einer E-Mail handelt? Diese Unklarheit ist oft der Beginn von schwer zu durchschauenden Abhängigkeiten. Im konkreten Fall stellte sich heraus, dass die Bestätigungs-E-Mail in den Email-Utils lag, allerdings war die Funktion darauf angewiesen, Funktionen aus den Payment-Utils aufzurufen, um den E-Mail-Inhalt korrekt zu generieren. Umgekehrt rief die Payment-Utils-Funktion wiederum die E-Mail-Funktion auf, um die Bestätigung zu versenden. Hier entsteht schnell eine zirkuläre Abhängigkeit zwischen den Modulen - eine klassische Falle in der Softwarearchitektur.
Warum sind zirkuläre Abhängigkeiten so problematisch? In vielen Programmiersprachen wie Python führt das zu Importfehlern, weil die Dateien beim Laufzeitimport sequentiell geladen werden müssen. Wird während des Ladens eines Moduls ein anderes Modul importiert, das wiederum versucht, das erste Modul zu laden, kann keine abschließende Definition der Funktionen garantiert werden. Die Folge ist ein Laufzeitfehler, der plötzlich an unerwarteten Stellen im Code auftaucht und die Fehlersuche extrem erschwert. Das Beispiel verdeutlicht, wie die vermeintlich praktische Gruppierung von Funktionen in horizontal geschnittenen Utils-Sammlungen letztlich zu komplexen, schwer wartbaren Abhängigkeiten führt. Entwickler sind mit Fehlern konfrontiert, die sich erst in späten Entwicklungsphasen zeigen und eine Menge Zeit für Debugging und Refactoring binden.
In produktiven Umgebungen kann dies zu Verzögerungen, nervenaufreibenden Fehlersuchen und im schlimmsten Fall zu instabiler Software führen. Wie lässt sich dieses Problem umgehen? Die Antwort liegt in der Umstrukturierung der Codebasis anhand einer vertikalen Modulsichtweise. Statt den Code entlang technischer Funktionsthemen wie „Emails“ oder „Payments“ horizontal zu trennen, sollten Module so aufgebaut werden, dass sie klare Geschäftsfunktionen oder Anwendungsbereiche vollständig kapseln. In einem solchen vertikalen Modul findet man dann alle relevanten Funktionen, Klassen und auch die spezifischen E-Mails, die beispielsweise zur Zahlungsabwicklung gehören. Diese Struktur orientiert sich an den Prinzipien des Domain-Driven Designs, das seinen Fokus auf die Geschäftslogik und die darin involvierten Akteure und Ereignisse legt.
Das bedeutet konkret, dass eine Zahlung nicht nur aus Zahlungslogik besteht, sondern auch sämtliche Nebenfunktionen wie das Versenden von Zahlungsbestätigungen beinhaltet. Auf diese Weise entfällt die Notwendigkeit für zirkuläre Abhängigkeiten, da alle relevanten Funktionen innerhalb desselben Moduls gekapselt sind. Neben der besseren Strukturierung hat die vertikale Aufteilung den Vorteil, dass sie die Autonomie der Module erhöht. Jedes Modul kann isoliert getestet, verändert oder erweitert werden, ohne das Risiko unvorhergesehener Nebenwirkungen in anderen Modulen. Darüber hinaus erleichtert die klare Trennung die Arbeit im Team, da Verantwortlichkeiten eindeutig sind und Entwickler sich auf klar abgegrenzte Bereiche konzentrieren können.
Natürlich behalten Utils in bestimmten Fällen ihre Berechtigung, nämlich dort, wo es um reine Hilfsfunktionen geht, die keine direkte Abhängigkeit zu bestimmten Geschäftsprozessen haben. Ein Beispiel wären generische Funktionen zum Versenden von E-Mails, zur Formatierung von Daten oder zum Umgang mit Zeitstempeln. Solche sogenannten „low level atoms“ sind universell nutzbar und sollten als eigenständige Hilfsbibliotheken neben den Geschäftsmodulen existieren. Zusammenfassend lässt sich sagen, dass die weit verbreitete Nutzung von Utils in der Softwareentwicklung oft mehr Probleme schafft, als sie löst. Die scheinbar einfache Handhabung und Gruppierung verbergen komplexe Abhängigkeitsfallen, die zu zirkulären Importen und schwer wartbarem Code führen.
Die klare Lösung liegt in einer bewussten Modulstruktur, die entlang der Domäne und der Geschäftslogik aufgebaut wird und so die Wartbarkeit, Lesbarkeit und Stabilität des Codes deutlich verbessert. Wer diese Prinzipien beachtet, der wird langfristig nicht nur weniger Zeit mit aufwändigen Refactorings verbringen, sondern auch qualitativ hochwertigere Software entwickeln. Es ist eine Investition in die Zukunft des Projektes und in die eigene Produktivität als Entwickler oder Entwicklungsteam. Das Beispiel mit Payment- und Email-Utils steht exemplarisch für viele ähnliche Situationen – sie verdeutlichen die Notwendigkeit eines Umdenkens in der Art und Weise, wie wir unsere Software strukturieren und organisieren.