Künstliche Intelligenz (KI) hat in den letzten Jahren enorme Fortschritte gemacht und beeinflusst zunehmend unser tägliches Leben. Besonders im Bereich der politischen Informationsverarbeitung kann KI eine wichtige Rolle spielen, sei es bei Nachrichtenauswahl, sozialen Medien oder automatisierten Entscheidungsprozessen. Dennoch zeigen immer mehr Studien und Berichte, dass KI-Systeme nicht neutral sind und politische Verzerrungen (Bias) aufweisen können. Interessanterweise unterscheiden sich diese Verzerrungen oft je nach Sprache und Kultur, in der die KI eingesetzt wird. Ein besonders aufschlussreicher Vergleich lässt sich anhand der englischen und französischen Sprachräume anstellen.
Diese beiden Sprachen sind weltweit verbreitet, haben aber unterschiedliche kulturelle und politische Hintergründe, was sich auch in den KI-basierten Interpretationen und Bewertungen widerspiegelt. Zunächst ist es wichtig zu verstehen, was politische Verzerrungen in KI bedeuten. Algorithmen lernen aus großen Datenmengen, die häufig Texte, Social-Media-Beiträge, Nachrichtenartikel und andere Formen menschlicher Kommunikation enthalten. Diese Daten spiegeln selbstverständlich die gesellschaftlichen Meinungen, Vorurteile und politischen Positionen wider. Dadurch übernehmen und verstärken KI-Systeme mitunter bestehende politische Einstellungen und können so eine bestimmte politische Richtung fälschlicherweise bevorzugen oder benachteiligen.
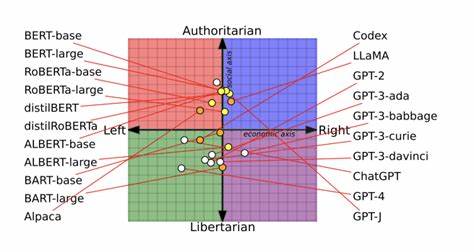
Dies hat unmittelbare Auswirkungen auf die Bevölkerung, denn die Nutzer erhalten verzerrte Informationen, was wiederum die öffentliche Meinungsbildung und demokratische Prozesse beeinflussen kann. Bei der Betrachtung des englischen und französischen Sprachraums fällt auf, dass die politischen Verzerrungen von KI in beiden Sprachen unterschiedliche Charakteristika aufweisen. Im englischsprachigen Raum, der insbesondere von den USA und Großbritannien geprägt wird, dominieren durchweg polarisiertere politische Standpunkte. Themen wie Liberalismus, Konservatismus, Bürgerrechte und wirtschaftliche Deregulierung führen dazu, dass KI-Modelle oft zwischen progressiven, mittleren und konservativen Inhalten unterscheiden müssen. Die große Präsenz sozialer Medien und Online-Diskussionsforen in englischer Sprache bietet zudem einen riesigen Datenpool, der allerdings auch extremeren Meinungen Raum gibt.
Dies kann dazu führen, dass KI in englischer Sprache mitunter radikalere politische Positionen häufiger aufnimmt und verstärkt. Im Gegensatz dazu zeigt sich im französischen Sprachraum eine andere politische Landschaft. Frankreich und andere frankophone Länder weisen oft ein höheres Maß an staatlicher Regulierung, soziale Sicherheit und historisch bedingt eine stärkere Betonung auf republikanische Werte. Das politische Spektrum unterscheidet sich in seiner Dynamik teilweise erheblich von der englischsprachigen Welt. Dementsprechend lernen KI-Modelle in französischer Sprache andere politische Prioritäten und Diskursmuster.
Häufig liegt der Schwerpunkt stärker auf sozialer Gerechtigkeit, Staatsinterventionen und kultureller Identität. Zudem sind die Debatten in französischer Sprache oft stärker durch intellektuelle Traditionen und philosophische Diskurse geprägt, was die Art und Weise beeinflusst, wie KI politische Inhalte verarbeitet. Die unterschiedlichen politischen Kontexte führen auch dazu, dass KI-Systeme bei der Interpretation von Nachrichten, Meinungsäußerungen und politischen Begriffen stark variieren. Beispielsweise hat der Begriff „liberal“ in englischer Sprache meist eine positive Konnotation des wirtschaftlichen Liberalismus, während er im französischen Sprachraum oft kritisch betrachtet wird, weil er als Synonym für Marktradikalismus stehen kann. Solche kulturellen Unterschiede führen dazu, dass KI-Modelle je nach Trainingsdaten unterschiedliche Gewichtungen und Assoziationen lernen, was die politische Bias-Entwicklung maßgeblich beeinflusst.
Darüber hinaus spielt die Auswahl der Datenquellen eine entscheidende Rolle. Englische KI-Modelle werden häufig mit Inhalten aus großen, globalen Plattformen wie Twitter, Reddit oder YouTube trainiert, die eine intensive politische Fragmentierung aufweisen. Französische Modelle ziehen oft auf fest verankerte Medienhäuser und offizielle Quellen zurück, die politischer und ideologisch etwas homogener sein können. Diese Unterschiede in den Trainingsdaten beeinflussen die Qualität und Art der politischen Verzerrungen, die in den jeweiligen Sprachmodellen zu finden sind. Technisch gesehen funktionieren die KI-Modelle in beiden Sprachen ähnlich, aber die zugrunde liegenden Daten und der kulturelle Kontext sind entscheidend.
Algorithmen neigen dazu, Muster in den Daten zu erkennen, ohne den tieferliegenden Kontext zu verstehen. Deshalb sind die Modelle in der englischen Sprache oft anfälliger für Polarisierung und politische Extreme, während französische Modelle eher eine moderate, staatszentrierte Sichtweise zu bevorzugen scheinen. Ein weiterer Aspekt betrifft die öffentlichen Reaktionen und Regulierungen in den jeweiligen Sprachräumen. In englischsprachigen Ländern wird der Diskurs über KI und politische Verzerrungen häufig hitziger geführt, was die Entwicklung von Transparenz- und Ausgleichsmechanismen beschleunigt. In französischsprachigen Ländern spielen politische Institutionen und Regulatoren eine aktivere Rolle bei der Überwachung und Steuerung von KI-Inhalten, was tendenziell zu einer stärkeren Eindämmung von politischen Verzerrungen in der Praxis führt.
Die Konsequenzen dieser unterschiedlichen Verzerrungen sind vielfältig. Menschen, die Informationen in Englisch konsumieren, sind verstärkt durch polarisierten Content gefährdet, der ihre politischen Einstellungen stärker extremisiert. Dies erschwert den gesellschaftlichen Dialog und fördert die Spaltung. Im französischen Sprachraum kann die Tendenz zu staatsnahen Positionen gleichzeitig zu einer Einschränkung der politischen Vielfalt führen, was demokratische Debatten ebenfalls beeinträchtigen kann. Es ist daher von großer Bedeutung, KI-Entwicklern und Forschern eine stärker kontextbewusste Arbeitsweise zu empfehlen, die neben sprachlichen Unterschieden auch kulturelle, politische und historische Hintergründe berücksichtigt.