Die Welt der Künstlichen Intelligenz hat in den letzten Jahren dank großskaliger Sprachmodelle, bekannt als Large Language Models (LLMs), eine regelrechte Revolution erlebt. Diese Modelle haben die Art und Weise, wie wir mit Maschinen interagieren, grundlegend verändert – sei es beim Verfassen von Texten, Beantworten von Fragen oder Automatisieren komplexer Aufgaben. Doch um das volle Potenzial eines LLM auszuschöpfen, reicht es nicht aus, das vortrainierte Modell einfach zu verwenden. Eine gezielte Feinabstimmung, auch Fine-Tuning genannt, und eine gründliche Evaluierung sind essenziell, um die Leistung optimal an spezifische Anwendungsbereiche anzupassen. In diesem Leitfaden werden die Grundlagen, Herausforderungen und effektivsten Methoden der Feinabstimmung und Evaluierung von LLMs detailliert erläutert und praxisnah vermittelt.
Zu Beginn ist es wichtig, die Evolution dieser Modelle nachzuvollziehen. Die Basis moderner LLMs bilden neuronale Netzwerke, deren Entwicklung einen weiten Weg zurücklegt. Während klassische Feedforward-Netzwerke bei sequentiellen Daten an ihre Grenzen stoßen, brachten Recurrent Neural Networks (RNNs) und ihre Erweiterung Long Short-Term Memory (LSTM) den Fortschritt, Abhängigkeiten über längere Textabschnitte zu erfassen. Dennoch konnten auch sie die heutigen komplexen Anforderungen nur teilweise erfüllen. Der Durchbruch kam mit der Transformer-Architektur, die sich durch das innovative Selbst-Aufmerksamkeitsverfahren (Self-Attention) auszeichnet.
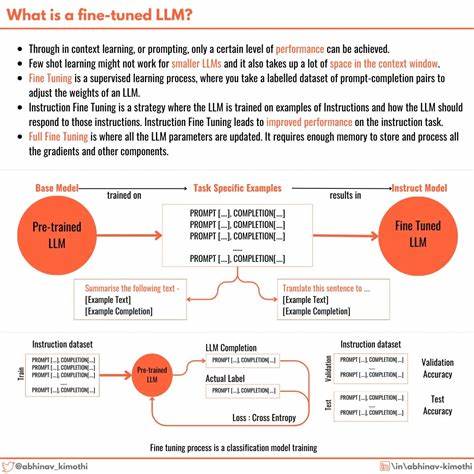
Dieses Verfahren erlaubt es dem Modell, die Beziehungen zwischen Wörtern unabhängig von ihrer Position im Satz zu erfassen und kontextuelle Verbindungen auf vielschichtige Weise zu verstehen. Multi-Head-Attention erweitert diesen Mechanismus, indem mehrere simultane Aufmerksamkeitshorizonte unterschiedliche Aspekte der Wortbeziehungen abbilden. Ergänzt wird dies durch die sogenannte Positionskodierung, welche die Reihenfolge der Wörter im Satz repräsentiert – ein entscheidender Faktor für den Sprachsinn. Die Feinabstimmung eines vortrainierten LLM ermöglicht es, seine generellen Fähigkeiten zielgerichtet für spezielle Anwendungen zu schärfen. Dabei wird das Modell auf maßgeschneiderten Daten nachtrainiert, um seine Antwortgenauigkeit, Sprachstil oder Fachkompetenz zu verbessern.
Der Übergang von der allgemeinen Vortrainierung zur spezialisierten Feinabstimmung erfordert jedoch sorgfältige Planung und Durchführung, denn zu viel Anpassung kann zum sogenannten Überanpassen (Overfitting) führen, was die Generalisierungsfähigkeit des Modells beeinträchtigt. Die Wahl der richtigen Fine-Tuning-Strategie hängt maßgeblich vom Anwendungszweck ab. Supervised Fine-Tuning, bei dem das Modell anhand gelabelter Beispieldaten trainiert wird, ist besonders geeignet für klar definierte Aufgaben wie Textklassifikation oder Frage-Antwort-Systeme. Wichtig dabei ist eine hochwertige und umfangreiche Datenbasis, da die Qualität der Trainingsdaten den größten Einfluss auf das Ergebnis hat. Während manuelle Datenaufbereitung sehr zeitintensiv sein kann, bieten heute verschiedene No-Code-Lösungen wie Ubiai die Möglichkeit, Fine-Tuning-Prozesse auch ohne tiefgehende Programmierkenntnisse durchzuführen.
Diese Tools erleichtern das Handling und ermöglichen eine intuitive Modellanpassung. Neben der Datenqualität sind einige Best Practices bei der Feinabstimmung zu beachten. Dabei spielen Aspekte wie die geeignete Wahl der Lernrate, Anzahl der Trainingsepochen und Kontrollmechanismen gegen Overfitting eine große Rolle. Zudem wird empfohlen, das Modell schrittweise und iterativ zu optimieren und Zwischenergebnisse stets mit geeigneten Metriken und menschlicher Evaluation zu überprüfen. Die Evaluation fertiger Modelle stellt einen ebenso wichtigen Bestandteil dar.
Hierfür existieren verschiedene Methoden, die von automatisierten Metriken bis hin zu qualitativen Bewertungen durch Experten reichen. Automatisierte Kennzahlen wie Genauigkeit, Präzision, Recall und der F1-Score helfen beim Vergleich unterschiedlicher Modelle und Versionen. Gleichzeitig ist die Einbeziehung von menschlichem Feedback unumgänglich, um die tatsächliche Sprachqualität, die Kohärenz und die Nutzerzufriedenheit beurteilen zu können. Ein weiterer zentraler Punkt bei der Feinabstimmung und Evaluation ist die Berücksichtigung der ethischen und sicherheitsrelevanten Aspekte. LLMs sind für ihre Tendenz bekannt, unbeabsichtigt schädliche oder voreingenommene Inhalte zu produzieren.
Deshalb sollte das Training und die Validierung sorgfältig so gestaltet werden, dass solche Risiken minimiert werden. Dazu gehören die Auswahl diverser und ausgewogener Trainingsdaten sowie das Implementieren von Filtermechanismen und Kontrollinstanzen. Durch den organisierten und systematischen Einsatz der beschriebenen Techniken und Strategien können LLMs effizient auf vielfältigste Branchenanforderungen zugeschnitten werden. Die Ergebnisse sind leistungsfähige Sprachmodelle, die sowohl in der Forschung als auch im praktischen Einsatz die Interaktion zwischen Mensch und Maschine deutlich bereichern. Zum Abschluss zeigt sich, dass die Feinabstimmung und Evaluation von Large Language Models keine rein technische Aufgabe ist, sondern ein vielschichtiger Prozess, der Wissen aus den Bereichen maschinelles Lernen, Linguistik, Datenwissenschaft und Ethik vereint.
Nur durch die Kombination all dieser Elemente entsteht ein intelligentes, robustes und verlässliches Modell, das seinen Anwendern echte Mehrwerte bietet und die Zukunft der KI mitgestaltet.