In den letzten Jahren hat die rasante Entwicklung im Bereich der Künstlichen Intelligenz (KI) insbesondere durch große Sprachmodelle (Large Language Models, LLMs) das Potenzial gezeigt, zahlreiche professionelle Disziplinen zu verändern. Neben Anwendungen in Medizin, Recht oder Technik rückt zunehmend die Chemie in den Fokus dieser Technologie. Die Frage, ob moderne KI-Modelle das chemische Wissen und die komplexen Denkprozesse von professionellen Chemikern erreichen oder sogar übertreffen können, gewinnt an Bedeutung – nicht nur für Wissenschaft und Industrie, sondern auch für die Bildung und den sicheren Umgang mit chemischen Substanzen im Alltag. Ein wegweisender Beitrag zu diesem Diskurs ist das neuartige Benchmark-System ChemBench, das gezielt die chemischen Fähigkeiten verschiedenster LLMs misst und diese mit der Expertise von menschlichen Chemikern vergleicht. Dabei wird erstmals ein umfassenderes und präziseres Bild der Stärken und Schwächen KI-basierter Systeme im chemischen Kontext zeichbar.
Große Sprachmodelle und ihr Potenzial in der Chemie Große Sprachmodelle wie GPT-4, Claude-3.5 oder offene Alternativen basieren auf dem Training mit enormen Textmengen. Sie lernen, Sätze mit sinnvollen Fortführungen zu vervollständigen, und können so auf verschiedenste Fragestellungen antworten – selbst auf solche, für die sie nicht explizit trainiert wurden. Im medizinischen Bereich ist ihr Erfolg in offiziellen Prüfungen bereits dokumentiert, und in der Chemie setzen immer mehr Forscher auf solche KI-Systeme, um Forschung zu beschleunigen, neue molekulare Verbindungen vorzuschlagen oder experimentelle Ansätze zu unterstützen. Zusätzlich werden LLMs zunehmend mit externen Tools kombiniert, die Zugriff auf chemische Datenbanken, Websuchmaschinen oder Codes zur Reaktionssimulation bieten.
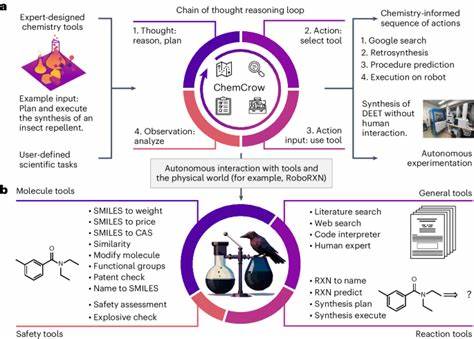
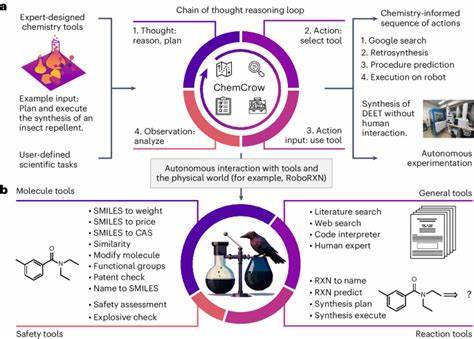
Dadurch wird ihre Leistungsfähigkeit erheblich erweitert, was das Potenzial zur Erstellung von sogenannten „Chemie-Copiloten“ unterstreicht – virtuellen Assistenten, die Chemiker bei komplexen Fragestellungen unterstützen oder sogar eigenständige Experimente steuern können. Trotz dieser Fortschritte bleibt jedoch unklar, wie gut die Modelle tatsächlich komplexes chemisches Wissen und insbesondere das chemische Denken beherrschen, das für verschiedenste Subdisziplinen innerhalb der Chemie notwendig ist. ChemBench: Ein neuartiger Benchmark für chemisches Wissen und Denken Die Einführung von ChemBench markiert eine wichtige Neuerung im Versuch, die Fähigkeiten der KI in der Chemie systematisch zu erfassen und vergleichbar zu machen. Das Benchmark besteht aus über 2700 sorgfältig kuratierten Frage-Antwort-Paaren, die ein breites Spektrum chemischer Themen abdecken – von allgemeiner über organische, anorganische bis hin zu analytischer und technischer Chemie. Abgedeckt sind Fragen, die Wissen, Berechnung, komplexe Schlussfolgerungen und chemische Intuition erfordern.
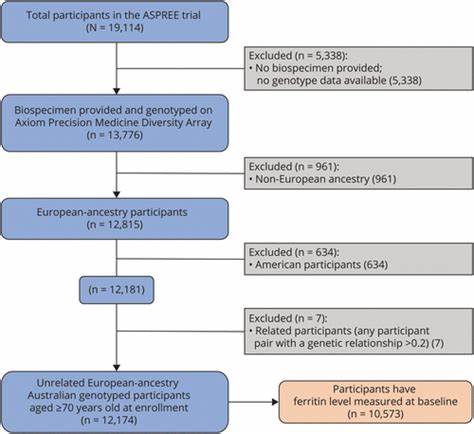
Sowohl Multiple-Choice-Fragen als auch offene Fragestellungen sind enthalten, um die Realität chemischer Fragestellungen abzubilden. Zur besseren Vergleichbarkeit mit menschlichen Experten wurde zudem eine vergleichbare Teilmenge namens ChemBench-Mini erstellt, welche von erfahrenen Chemikern beantwortet wurde. Einige der Experten durften dabei auch moderne Hilfsmittel wie Webrecherche oder chemiespezifische Software verwenden, um praxisnahe Bedingungen zu simulieren. Leistungsfähigkeit moderner Sprachmodelle im Vergleich zu Chemikern Eine der bemerkenswertesten Erkenntnisse zeigt sich in der Gesamtleistung der modernsten LLMs: Das führende Modell „o1-preview“ lag im Durchschnitt deutlich über den Ergebnissen der menschlichen Chemieexperten. Auch andere Spitzensysteme wie Llama-3.
1-405B-Instruct zeigten Leistungswerte nahe an denen der besten proprietären Modelle, was bestätigt, dass auch offene Modelle mittlerweile eine Bedeutung im professionellen Umfeld erlangen. Dennoch offenbaren Tests, dass gerade bei grundlegendem Faktenwissen die Modelle oft Schwierigkeiten haben, korrekte Informationen abzurufen. Hier offenbart sich die unzureichende Abdeckung spezialisierter Datenbanken wie PubChem oder Gestis, die selbst für professionelle Chemiker unverzichtbar sind. Dies legt nahe, dass eine stärkere Integration spezialisierter Wissensquellen oder deren Einbindung in den Trainingsprozess der KI dringend erforderlich ist. Besonders interessant ist die große Heterogenität der Modellleistung innerhalb verschiedener chemischer Fachgebiete.
Während viele Modelle in allgemeinen und technischen Chemiethemen vergleichsweise gut abschneiden, liegen ihre Leistungen im Bereich der chemischen Sicherheit, Toxikologie oder analytischen Chemie deutlich unter den Erwartungen. Die Fähigkeit beispielsweise, die Anzahl von Signalen in einem Kernspinresonanz-Spektrum korrekt zu prognostizieren, gehört weiterhin zu den Herausforderungen selbst für die besten LLMs. Leistung und Lernverhalten der Modelle: Kein linearer Zusammenhang mit Molekülkomplexität Eine weitere Erkenntnis betrifft die Modelllogik bei der Beantwortung komplexer chemischer Fragen, die sich auf molekulare Strukturen stützen. Idealerweise sollten Modelle je nach Komplexität eines Moleküls differenzierte Antworten liefern können. Doch die Untersuchungen zeigen, dass die Leistung kaum mit Größenindikatoren der Molekülkomplexität korreliert.
Dies spricht dafür, dass viele Sprachmodelle nicht wirklich „verstehen“, sondern eher Muster und Ähnlichkeiten zu zuvor gesehenem Text nutzen, um Antworten zu generieren. Diese Erkenntnis unterstreicht die wichtige Unterscheidung zwischen bloßem Reproduzieren von Informationen und echtem chemischem Intellekt. Die Grenzen der Modelle in der Einschätzung eigener Zuverlässigkeit Ein kritischer Faktor für den praktischen Einsatz von KI-Systemen ist deren Fähigkeit, die Verlässlichkeit ihrer eigenen Antworten einzuschätzen. Eine gut kalibrierte Selbstbewertung könnte falsche oder riskante Aussagen minimieren, insbesondere im sicherheitsrelevanten Umfeld der Chemie. Die Analysen mittels verbalisierten Vertrauensskalen ergaben jedoch, dass viele führende Modelle kein verlässliches Bild ihrer eigenen Unsicherheit abgeben.
Insgesamt fehlt es an einem klaren Zusammenhang zwischen hoher Selbstsicherheit und korrekten Antworten. In einigen Fällen gaben die Modelle auf falsche Antworten sogar eine höhere Selbstsicherheit als auf richtige Antworten an, was für den Einsatz in kritischen Anwendungen hohe Risiken birgt. Chancen und Herausforderungen für Ausbildung und Forschung Die Erfolge der LLMs auf typischen Lehrbuchfragen und Multiple-Choice-Klausursets legen nahe, dass traditionelle Prüfungen an Hochschulen und Universitäten womöglich neu überdacht werden müssen. Solche Prüfungen messen oft Faktenwissen und Routineaufgaben ab, bei denen Sprachmodelle mittlerweile den Menschen weit überlegen sind. Damit rückt die Förderung von kritischem Denken, komplexem Problemlösen und der praktischen Anwendung in den Vordergrund – Fähigkeiten, die auch für künftige Chemiker unersetzlich bleiben.
Für die Forschung bieten fortgeschrittene Sprachmodelle enormes Potenzial. Von der automatisierten Literaturrecherche über das Extrahieren verborgener Erkenntnisse in wissenschaftlichen Texten bis zur Planung komplexer Synthesen können solche Systeme als Unterstützung dienen. Die Kombination aus Maschinenintelligenz und menschlicher Kreativität hat das Potenzial, Innovationszyklen zu verkürzen und die Entdeckung neuer Materialien oder Wirkstoffe zu beschleunigen. Dennoch gilt es, die Grenzen heutiger Modelle kritisch zu beachten und einen verantwortungsvollen Umgang zu fördern. Die Gefahr von Fehlinformationen, insbesondere im Bereich Chemikaliensicherheit, kann zu erheblichen Risiken für Anwenderinnen und Anwender sowie die Umwelt führen.
Deshalb ist die Entwicklung von Evaluations- und Zertifizierungsverfahren sowie von erweiterten Benchmark-Frameworks wie ChemBench essenziell, um Fortschritte messbar zu machen und Missbrauch zu verhindern. Ausblick: Integration, Skalierung und menschliche Zusammenarbeit Die Entwicklung speziell auf Chemie ausgerichteter Sprachmodelle steht noch am Anfang. Erste Ergebnisse weisen jedoch auf eine wachsende Leistungsfähigkeit mit zunehmender Modellgröße und Trainingsdaten hin. Wichtig erscheint vor allem die Integration spezialisierter Datenbanken und die Nutzung multimodaler Daten – also neben reinem Text auch Strukturen, Gleichungen und Experimentaldaten. Gleichzeitig wird die Zusammenarbeit zwischen Maschinen und Menschen weiterhin eine Schlüsselrolle spielen.