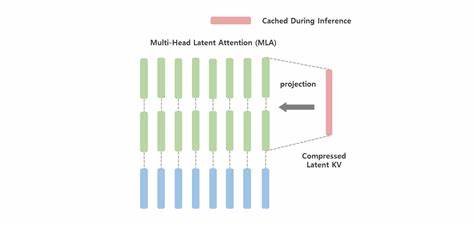
Mit dem Aufstieg großer Sprachmodelle (Large Language Models, LLMs) wächst auch die Herausforderung, immer effizientere Speichertechniken zu entwickeln, um den starken Bedarf an Videospeicher (VRAM) während der Inferenz zu bewältigen. Besonders bei langen Kontextlängen führen die Key-Value-Caches (K/V-Cache) dazu, dass die Speicheranforderungen exponentiell ansteigen. Das traditionelle Speichern aller Keys und Values für jeden Token und jede Aufmerksamkeitsebene verbraucht enorm viel Speicher und limitiert somit die Skalierbarkeit und Leistung moderner Transformer-basierter KI-Modelle. Genau an dieser Stelle zeigt MLA (Multi-Head Latent Attention) mit der Technik der Low-Rank-Projektion und on-demand Dekompression seine Stärken und revolutioniert die Art und Weise, wie K/V-Caches gehandhabt werden können.Der K/V-Cache ist essenziell für die effiziente Berechnung von Aufmerksamkeitsmechanismen bei autoregressiven Decodern.
Während der Token-Generierung müssen die Keys und Values der bisherigen Token zwischengespeichert werden, um sie für nachfolgende Schrittberechnungen schnell verfügbar zu halten. Bei klassischen Multi-Head Attention (MHA) haben alle Attention-Heads eigene Key- und Value-Repräsentationen, was den Speicherbedarf linear mit der Anzahl der Heads und der Kontextlänge anwachsen lässt. Diese Situation wird spätestens bei Sequenzen von mehreren Tausend Tokens kritisch, da der gesamte Inhalt des K/V-Caches schnell VRAM-Grenzen auf Verbraucherseite überschreiten kann.Frühere Lösungen wie Multi-Query Attention (MQA) und Grouped-Query Attention (GQA) versuchten, den Speicherbedarf durch Kopf-übergreifendes Teilen von K/V-Informationen zu verringern. MQA setzte alle Heads auf eine gemeinsame K/V-Repräsentation, was den Speicherverbrauch signifikant reduzierte, dabei aber teilweise die Ausdrucksstärke der Köpfe beeinträchtigen konnte.
GQA bot eine Zwischenlösung, in der Kopfgruppen jeweils eine gemeinsame K/V-Struktur nutzen, um einen Kompromiss zwischen Speicherersparnis und Modellleistung zu erzielen. Trotz dieser Bemühungen bleiben Limits bestehen, da bei zunehmenden Heads der Speicherbedarf weiterhin beträchtlich bleibt.MLA setzt an einem anderen Punkt an. Statt ausschließlich den Grad der K/V-Sharing zu überdenken, geht MLA einen Schritt weiter und hinterfragt, was überhaupt gespeichert wird. Die Kernidee ist, dass nicht alle Informationen im ursprünglichen High-Dimensionalen K/V-Space als Ganzes zwischengespeichert werden müssen, sondern dass eine stärkere Komprimierung durch niedrigdimensionale Repräsentationen möglich ist.
Hierbei wird an Stelle der klassischen K/V-Vektoren ein sogenannter latenter Vektor gespeichert, der durch eine Low-Rank-Projektion aus den Eingabedaten erzeugt wird. Diese latenten Vektoren besitzen eine deutlich geringere Dimension und somit einen wesentlich kleineren Speicherbedarf.Das MLA-Modell wendet dabei eine Low-Rank-Projektion im Trainingsprozess an, um den Input-Token auf einen kompakten latenten Vektor zu transformieren. Anschließend werden für jeden Attention-Head während der Inferenz explizite Key- und Value-Vektoren on-demand rekonstruiert, indem der latente Vektor mit den jeweiligen Projektionsmatrizen kombiniert wird. Dieser sogenannte Matrix-Merging-Trick erlaubt es, die eigentlichen K/V-Arrays nicht vollständig im VRAM vorzuhalten, sondern bei Bedarf aus kleineren, gespeicherten Latenzvektoren „aufzufalten“.
Dadurch sinkt die VRAM-Belastung drastisch – je nach Anwendung und Kompressionsgrad um den Faktor acht oder höher.Zusätzlich berücksichtigt MLA wichtige Architekturfeatures wie RoPE (Rotary Position Embedding). RoPE ist eine weitverbreitete Methode, um Positionsinformationen in den Key- und Query-Vektoren zu verankern, was insbesondere für die Modellierung von langen Abhängigkeiten essenziell ist. Die Integration von RoPE in das Low-Rank-Setup erfordert eine clevere Aufteilung der latent gespeicherten Daten: Ein Teil wird als räumlich-zeitlicher Positionsanteil („Position Sticker“) separat behandelt, um die relative Positionsinformation akkurat zu bewahren. Durch diese Split-Strategie entstehen keine Verluste bei der Positionskodierung, während der Hauptspeicher weiterhin von der Low-Rank-Komprimierung profitiert.
Dieses Zusammenspiel aus latenter Speicherung und auf Abruf erfolgender Dekompression bietet neben einer signifikanten VRAM-Einsparung auch Möglichkeiten einer verbesserten Skalierbarkeit. Ein einziger GPU-Speicherplatz kann nun größere oder längere Kontextfenster verarbeiten und erlaubt zudem, durch verminderte Bandbreitenbelastung bei der Speicherzugriffsrate, schnelleres Inferencing. Der Bedarf, den K/V-Cache über mehrere GPUs zu verteilen, wird verringert, was Kommunikation und Synchronisation vereinfachen kann.Die technische Umsetzung von MLA zeigt sich in modularen Transformer-Bibliotheken, beispielsweise in der DeepSeek-Implementierung. Dort stechen einige Verbesserungen wie die Kombination von RMSNorm-Normalisierungen mit Low-Rank-Layern hervor, die gemeinsam robuste und stabile Trainings- und Inferenzprozesse ermöglichen.
Zudem lässt sich MLA mit anderen Optimierungen vereinen, etwa Quantisierung oder Sparse-Experten (MoE), wodurch insgesamt eine hohe Effizienz bei gleichzeitig variabler Leistungsfähigkeit entsteht.MLA ist besonders vielversprechend für Anwendungen mit extrem langen Kontexten, bei welchen die bisherige K/V-Cache-Strategien an Grenzen stoßen. Ob das Modell tausende Tokens kontextuell erfassen soll für komplexe Textgenerierung oder detaillierte sequenzielle Analysen – durch die stark reduzierte Speichernutzung können längere Abschnitte erfasst und verarbeitet werden, ohne die Hardware-Anforderungen massiv zu erhöhen.Darüber hinaus ist die Speicherreduktion durch MLA auch energiesparend und kostensenkend. Weniger VRAM-Nutzung bedeutet meistens auch eine geringere Wärmeentwicklung und damit längere Lebensdauer der eingesetzten Grafikprozessoren.
Anwender können kostspielige High-End-GPUs besser auslasten oder auf günstigere Hardware übergehen, was wiederum einen niedrigeren Investitions- und Betriebskostenrahmen erlaubt.Ein zusätzlicher Vorteil von MLA besteht in der Flexibilität, verschiedene Positionierungssysteme einzubinden. Neben RoPE sind auch andere Positional Encoding-Methoden wie ALiBi oder NTK Scaling denkbar, die wiederum mit der latenten K/V-Codierung harmonieren. Das ermöglicht eine breite Einsetzbarkeit und Anpassungsfähigkeit an spezifische Modelle und Aufgaben.Aus Sicht des Software-Engineerings stellt MLA zudem einen einfachen und wartbaren Lösungsansatz dar.
Kernkomponenten wie Low-Rank-Projektionsmatrizen und Dekompressionslogiken sind klar getrennt und gut verständlich. Die Verwendung von Matrixmultiplikationen ermöglicht eine effiziente GPU-Nutzung und einfache Integration in gängige Deep-Learning-Frameworks wie PyTorch. Dies erleichtert Entwicklern, das Konzept zu adaptieren und an individuelle Anforderungen anzupassen.Natürlich bringt MLA auch einige Herausforderungen mit sich. Die Aufteilung der RoPE-Dimensionen und die genaue Bestimmung der latenten Dimension erfordern meist experimentelle Verfeinerungen, um ein optimales Verhältnis aus Positionsgenauigkeit und Speicherkompression zu erzielen.
Zudem können numerische Ungenauigkeiten bei der mehrfachen Matrixmultiplikation unter Mixed-Precision auftreten, was bei sehr anspruchsvollen Anwendungen eine Rolle spielen kann. Hier helfen jedoch moderne mathematische Techniken und Precision Management, die Effekte auf ein tolerierbares Minimum zu reduzieren.Zusammenfassend lässt sich sagen, dass die Multi-Head Latent Attention mit Low-Rank-Projektion eine innovative und effektive Methode darstellt, um den kritischen K/V-Speicherbedarf bei Transformer-basierten Modellen erheblich zu reduzieren, ohne dabei signifikante Kompromisse in der Modellperformance einzugehen. Durch das Speichern von kompakten latenten Vektoren statt kompletter Multi-Head K/V-Daten und die Integration von on-demand Dekompression wird eine bessere Skalierbarkeit bei langen Kontexten erreicht und gleichzeitig VRAM und Bandbreitenressourcen geschont. Die intelligente Einbindung von Positionsinformationen sichert die Modellgenauigkeit ab und bietet flexible Einsatzmöglichkeiten.
MLA könnte somit eine Schlüsselrolle in der Zukunft der effizienten KI-Inferenz spielen, insbesondere in Zeiten, in denen der Bedarf an großem Kontext und geringer Latenz stetig wächst.



![Known pitfalls in C++26 contracts [video]](/images/58A769E3-7A18-4766-90AD-28E0B476B02E)




