Die Entwicklung von Software hat sich in den letzten Jahrzehnten kontinuierlich gewandelt, doch die Grundprinzipien des Testens blieben meist unverändert. Klassische Teststrategien basieren auf der Annahme, dass Code von Menschen geschrieben wird, was bestimmte Muster der Fehlerentstehung und -behebung mit sich bringt. Die neuen Technologien, insbesondere große Sprachmodelle (Large Language Models, LLMs) zur Codegenerierung, bringen jedoch einen radikalen Wandel in den Entwicklungsprozess und stellen die traditionelle Softwaretestlandschaft vor enorme Herausforderungen. Die Art und Weise, wie LLMs Code generieren, unterscheidet sich grundlegend von menschlicher Softwareentwicklung. Während Entwickler inkrementell und iterativ arbeiten, bauen LLMs den Quellcode sequenziell auf, wobei jeder Token auf den vorherigen Entscheidungen basiert.
Diese auto-regressive Natur führt dazu, dass die Effektive Spezifikation eines Codes nicht nur durch die ursprüngliche Eingabe – oft ein kurzer Prompt – definiert ist, sondern durch die Kombination aus Prompt und bereits erzeugtem Codeabschnitt. Dies bedeutet, dass die Entstehung des Codes eine Art selbstreferenziellen Prozess durchläuft, der neue, komplexe Fehlerquellen schafft. Ein menschlicher Programmierer gliedert häufig komplexe Funktionen in überschaubare Einheiten, wodurch sich jeder Abschnitt gezielt testen und validieren lässt. LLMs hingegen erzeugen oft Codeblöcke, die in sich verstrickt sind und bei denen einzelne Funktionalitäten eng miteinander verbunden sind, ohne klare Trennung. Das erschwert das isolierte Testen durch herkömmliche Unit-Tests.
Beispielsweise kann der Algorithmus zum Sortieren in direkter Wechselwirkung mit der Medianberechnung stehen, was zu fehlerhaften Ergebnissen bei bestimmten Eingabedaten führt, die sich mit klassischen Testmethoden nur schwer reproduzieren lassen. Zusätzlich stellen die von KI erzeugten Codebasis in der Regel ein Vielfaches an Volumen dar im Vergleich zu inkrementellen menschlichen Entwicklungen. LLMs können binnen Sekunden mehrere hundert oder tausend Zeilen Code generieren, die als zusammenhängendes Artefakt betrachtet werden müssen. Die Komplexität solcher Gesamtsysteme führt dazu, dass sich Fehler oft nicht einfach auf lokale Module oder Funktionen beschränken lassen, sondern das Zusammenspiel zwischen verschiedenen Komponenten betreffen. Das traditionelle Konzept der Codeabdeckung verliert an Aussagekraft, wenn die Abhängigkeiten und Zustandsübergänge zwischen Modulen sehr komplex und dynamisch sind.
Die Art der auftretenden Fehler ändert sich ebenfalls signifikant. Während menschliche Fehler häufig syntaktischer oder einfacher logischer Natur sind, erzeugt KI-basierter Code oft subtilere semantische Inkonsistenzen. Diese können sich nur unter bestimmten Bedingungen oder Eingabeszenarien zeigen, was die Identifikation und Behebung erheblich erschwert. Die Fehler sind häufig Folge von inkonsistenten Annahmen, die das Modell während des Generierungsprozesses trifft, und den sich daraus ergebenden Seiteneffekten im Gesamtsystem. Diese Transformation erfordert ein grundlegendes Umdenken in der Teststrategie und in der Entwicklung passender Werkzeuge und Techniken.
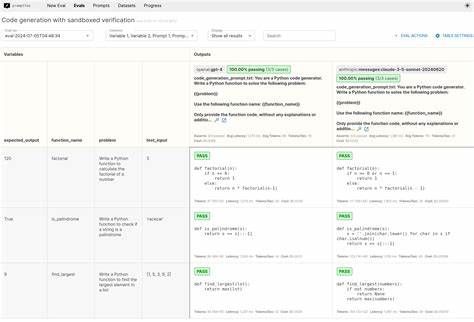
Klassische Softwaretests, die sich auf inkrementelle Änderungen, lokale Codebereiche und klare Schnittstellen konzentrieren, sind für LLM-generierten Code oft ineffektiv. Stattdessen müssen Tests zunehmend system- und kontextbezogen sein, die globale Verhaltensweisen analysieren und emergente Eigenschaften erkennen können. Moderne Tools im Bereich der KI-gestützten Softwareverifikation nutzen maschinelles Lernen und andere intelligente Verfahren, um Muster im Verhalten des generierten Codes zu erkennen. Automatisierte Testfallgenerierung kann dabei helfen, edge cases zu identifizieren, die von menschlichen Testern möglicherweise übersehen werden. Gleichzeitig gewinnen Techniken wie Property-Based Testing an Bedeutung, bei denen Eigenschaften definiert werden, die der Code unabhängig von der Implementierung immer erfüllen muss, anstatt einzelner erwarteter Ausgaben.
Ein weiterer vielversprechender Ansatz ist die Integration von formaler Methoden zur Verifikation in den Entwicklungsprozess. Während vollständige formale Überprüfungen bislang oft zu aufwendig waren, könnte die Kombination mit KI-gestützten Ansätzen dazu beitragen, Teilbereiche eines großen generierten Codes systematisch abzusichern. So können kritische Komponenten validiert werden, bevor der gesamte Code in komplexe Systeme integriert wird. Zur Bewältigung der großen Masse an Code ist die Testautomatisierung essenziell. Continuous Integration und Continuous Deployment (CI/CD) Pipelines müssen erweitert werden, um nicht nur statische Prüfungen, sondern auch dynamische Tests mit komplexer Umfeldsimulation zu unterstützen.
Dabei ist es wichtig, dass die Testumgebung die echten Einsatzbedingungen möglichst genau spiegelt, um emergente Fehler sichtbar zu machen. Die Rolle des menschlichen Entwicklers wandelt sich durch diese Entwicklungen ebenfalls. Weniger im Fokus steht die manuelle Codierung einzelner Algorithmen, sondern vielmehr das Design von prompts, die das Sprachmodell zielgerichtet anleiten und steuern. Gleichzeitig wird das menschliche Verständnis von Systemarchitektur und spezifikationsorientierter Softwareentwicklung entscheidend, um die automatisch generierten Artefakte sinnvoll zu prüfen und zu bewerten. Schließlich wirft die Nutzung von KI-generiertem Code auch ethische und rechtliche Fragestellungen auf, die indirekt die Testpraxis beeinflussen.
Verantwortlichkeit für Fehler, Fragen zum Urheberrecht und Datenschutz fließen in den gesamten Software-Lifecycle ein und verlangen klare Richtlinien und Standards. Die Zukunft des Softwaretestens im Zeitalter von KI-generiertem Code verspricht also nicht nur technische Innovationen, sondern auch eine grundlegende Verschiebung im Verständnis von Entwicklungs- und Verifikationsprozessen. Um wettbewerbsfähig zu bleiben und qualitativ hochwertige Software bereitzustellen, müssen Unternehmen und Entwickler auf neue Methoden setzen, die speziell auf die Charakteristika von LLM-generiertem Code ausgerichtet sind. Nur so lässt sich das volle Potenzial der KI-Technologie nutzen und gleichzeitig die Stabilität und Sicherheit moderner Software gewährleisten.