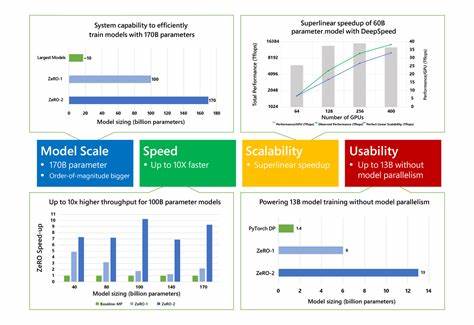
Recurrent Neural Networks (RNNs) sind seit Jahrzehnten ein wichtiger Bestandteil der Künstlichen Intelligenz, insbesondere im Bereich der Verarbeitung sequenzieller Daten wie Sprache, Text oder Zeitreihen. Ihre Fähigkeit, Informationen aus einer Sequenz langfristig zu erfassen, macht sie in vielen Anwendungen unverzichtbar. Doch während die Popularität von Transformer-Modellen in jüngster Zeit exponentiell wächst, bleiben RNNs aufgrund ihrer inhärenten Architektur in einigen Szenarien weiterhin überlegen, vor allem wenn es um effiziente Nutzung von Speicher und Rechenzeit bei langen Kontexten geht. Einer der großen Vorteile von RNNs gegenüber Transformern ist ihre konstante Skalierung bei der Inferenz in Bezug auf FLOPs (Floating Point Operations Per Second) und GPU-Speicherbedarf. Während Transformer-Modelle bei jedem zusätzlichen Token in der Sequenz zwangsläufig die Aufmerksamkeit auf alle vorherigen Tokens rechenintensiv neu berechnen müssen, bündeln RNNs frühere Kontextinformationen in einem fixed-size-State, wodurch die Kosten der Inferenz weitgehend unverändert bleiben.
Dennoch ist der Trainingsprozess von RNNs mit sehr langen Kontexten eine Mammutaufgabe und bisher ein klarer Engpass. Dieser Trainingsengpass ergibt sich hauptsächlich aus der Notwendigkeit der sogenannten Backpropagation Through Time (BPTT). BPTT erfordert, dass während der Vorwärtspassage des Netzwerks sämtliche Zwischenergebnisse und Zustände gespeichert werden, um spätere Gradientenberechnungen korrekt durchzuführen. Die Folge ist erheblicher Speicher- und Rechenaufwand, der mit zunehmender Kontextlänge und Modellgröße linear ansteigt. Diese Einschränkung schränkt die Skalierbarkeit von RNNs erheblich ein und hat bisher große, leistungsfähige RNN-Modelle weitgehend verhindert.
Hier schlägt die neuartige Methode der Zero-Order-Optimierung ein neues Kapitel auf. Insbesondere Techniken wie Random-vector Gradient Estimation (RGE) ermöglichen eine komplette Umgehung von BPTT. Statt wie bisher anhand gespeicherter Aktivierungen Gradienten zu berechnen, verlassen sich Zero-Order-Methoden auf zufällige Störungen der Parameter und beobachten die resultierenden Änderungen des Verlustes. Diese Methode ist bedeutend speichereffizienter, da keine Zwischenspeicherung der Forward-Pass-Aktivierungen notwendig ist. Das Modell befindet sich während des Trainings tatsächlich im sogenannten Inferenzmodus, was einen erheblichen Vorteil bei der Skalierung bedeutet.
Die Resultate, die mit Zero-Order Optimierung erzielt werden, sind erstaunlich. Studien zeigen, dass die Konvergenzrate gegenüber BPTT im besten Fall bis zu 19-fach gesteigert werden kann. Zudem wird mit dieser Methode ein deutlicher Rückgang des Speicherverbrauchs bei gleichzeitig niedrigeren Kosten erreicht. Dies ist besonders bemerkenswert, da der Trainingsprozess trotz des erhöhten Bedarfs an Forward-Pässen pro Optimierungsschritt im Gesamtvergleich schneller sein kann als herkömmliches BPTT-basiertes Training, insbesondere wenn neueste Technologien wie FlashRNN und verteilt arbeitende inference-basierte Prozesse zum Einsatz kommen. Ein weiteres interessantes Konzept stellt die Central-Difference RGE (CD-RGE) dar, welche im Kern ein geglättetes Surrogat des eigentlichen Verlustberichts optimiert.
Dies führt zu einer inhärenten Regularisierung des Trainingsprozesses, was wiederum eine verbesserte Generalisierungsfähigkeit der trainierten Modelle zur Folge hat. Sie zeigen in diversen Anwendungsszenarien – darunter Overfitting-Prävention, Transduktionsaufgaben sowie Sprachmodellierung – teils bessere oder zumindest vergleichbare Leistungen zu früh etablierten BPTT-basierten Verfahren. Die Bedeutung dieser Entwicklung lässt sich kaum überschätzen. Große Sprach- und Sequenzmodelle mit Milliarden von Parametern effizient zu trainieren, war bislang nach wie vor mit massiven technischen Herausforderungen verbunden. Zero-Order Optimierung hebt diese Barriere auf und bietet einen gangbaren Weg, der wichtige Vorteile in Bezug auf Ressourcenschonung und Trainingseffizienz vereint.
Für Forschungseinrichtungen und Unternehmen ist dies eine Möglichkeit, modernste Modelle mit größerer Kontextualität und Ausdruckskraft zu entwickeln, ohne auf teure Hochleistungs-Hardware angewiesen zu sein. Darüber hinaus erlaubt die reduzierte Kopplung an lange Backpropagation-Strecken eine bessere Skalierung der RNNs in wirklich langen Abhängigkeiten und Sequenzen. Während Transformer-Modelle bei enormen Sequenzen aufgrund ihres quadratischen Komplexitätsverhaltens oft an Effizienzgrenzen stoßen, setzen nun optimierte RNN-Strukturen mit Zero-Order-Methoden neue Maßstäbe bei Trainings- und Inferenzgeschwindigkeiten. Die Integration solcher Methoden ist auch ein Aufruf mehr Aufmerksamkeit auf Alternativen zu BPTT zu richten, die lange Zeit als unverzichtbarer Standard galten. Die vielversprechenden Ergebnisse von Zero-Order Optimierung werden daher langfristig das Entwicklungsfeld der neuronalen Netzwerke erweitern und verändern, nicht nur für RNNs, sondern vielleicht auch für andere Modellarchitekturen.
Aktuelle Forschungsbemühungen konzentrieren sich deshalb auf die weitere Automatisierung, Stabilisierung und Skalierung dieser Verfahren. Insbesondere die Kombination von Zero-Order-Methoden mit verteilter Trainingsinfrastruktur und spezialisierten Hardwarebeschleunigern verspricht einen Durchbruch bei der Entwicklung besonders großer und leistungsfähiger KI-Modelle. Die Herausforderung besteht darin, auch bei enormen Modellgrößen eine gleichbleibende Trainingsstabilität und funktionale Generalisierung zu gewährleisten. Abschließend zeigt sich, dass die Skalierung von RNNs auf Milliarden von Parametern durch Zero-Order Optimierung einen Paradigmenwechsel darstellt. Sie verbindet Vorteile des RNN-Designs mit innovativen, speichereffizienten Optimierungsmethoden und ebnet so den Weg für eine neue Generation an KI-Modellen, die effizienter, leistungsfähiger und zugänglicher sind.
Dies wird nicht nur die Forschung beflügeln, sondern auch die praktische Anwendung von KI-Technologien in unterschiedlichsten Branchen revolutionieren.





![Atomic Trampoline Reactor [pdf]](/images/15C8D3B8-317B-4BA7-B643-591C666FC5EF)
