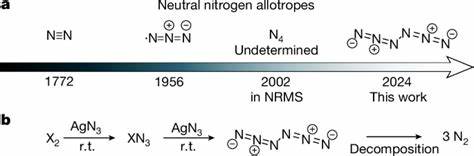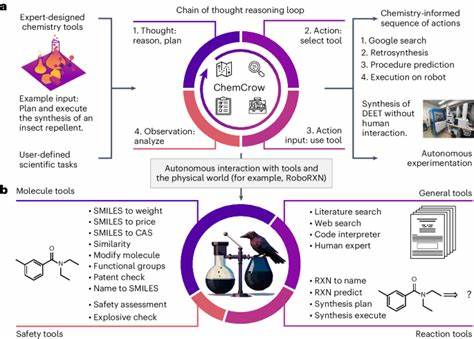
Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat im wissenschaftlichen Bereich und speziell in den Naturwissenschaften große Aufmerksamkeit erregt. Chemie, als eine der zentralen Naturwissenschaften, stellt dabei besondere Anforderungen, da sie nicht nur umfangreiches Fachwissen, sondern auch ausgeprägte logische und intuitive Fähigkeiten erfordert. Der Vergleich zwischen der Expertise erfahrener Chemiker und den chemischen Kompetenzen moderner LLMs steht daher im Mittelpunkt zahlreicher Forschungsprojekte und Diskussionen. Große Sprachmodelle basieren auf neuronalen Netzen, die mit enormen Mengen an Textdaten trainiert werden. Dabei lernen sie Muster und Zusammenhänge in der Sprache, ohne spezifisch auf Chemie trainiert zu sein.
Durch diesen universellen Lernansatz können sie Fragen auf vielfältigen Gebieten beantworten. Doch wie gut können diese Systeme in einem derart spezialisierten und komplexen Gebiet wie der Chemie wirklich bestehen? Können sie das Wissen und die Schlussfolgerungen menschlicher Experten übertreffen oder sogar ersetzen? Aktuelle Forschungen, wie die im Nature Chemistry veröffentlichte Studie zu ChemBench, einem speziell entwickelten Benchmark zur Bewertung der chemischen Kenntnisse und des logischen Denkens von LLMs im Vergleich zu menschlichen Chemikern, geben spannende Einblicke. Die Autoren stellten über 2700 Fragen unterschiedlicher Art zusammen, die von grundlegenden Wissensthemen bis hin zu komplexen Fragestellungen mit Berechnung, Argumentation und Intuition reichten. Die Resultate zeigen, dass führende Modelle in der Lage sind, durchschnittliche menschliche Chemiker zu übertreffen, was die reine Wissensbasis und einfache Aufgaben angeht. Dabei können sie insbesondere Fragen aus der allgemeinen und technischen Chemie erstaunlich gut beantworten.
Diese Überlegenheit ist jedoch nicht uneingeschränkt. Die Modelle haben Schwierigkeiten mit Aufgaben, die tiefere chemische Reasoning-Fähigkeiten erfordern oder mit Aufgaben, die spezielle Datenbanken und externe Referenzen benötigen, um korrekt beantwortet zu werden. So fällt es den LLMs zum Beispiel schwer, genaue Voraussagen in der analytischen Chemie zu treffen, wie z.B. komplexe NMR-Spektren zu interpretieren oder die Anzahl der relevanten Signale zu bestimmen.
Dies zeigt, dass trotz der enormen Textmengen in den Trainingsdaten das reine Sprachmodellieren nicht genügt, um die komplexe molekulare Struktur und ihre Implikationen vollständig zu erfassen. Besonders interessant ist die Erkenntnis, dass die Modelle häufig übermäßiges Selbstvertrauen in ihre eigenen Antworten zeigen, obwohl diese mitunter falsch sind. Dies ist ein kritischer Punkt, da eine falsche Sicherheit in den Ausgaben von KI-Systemen gerade in sicherheitsrelevanten Feldern wie der Chemie große Risiken birgt. Chemische Sicherheit und Toxizitätsfragen erfordern nicht nur Wissen, sondern auch eine verantwortungsvolle Einschätzung, um Gefahren für Patienten, Nutzer oder Umwelt zu vermeiden. Weiterhin zeigt die Studie, dass die Leistung der Modelle stark mit deren Größe korreliert, was nahelegt, dass durch weitere Skalierung und Integration spezieller Datenquellen noch Verbesserungen möglich sind.
Dennoch scheint die rein datengetriebene Verbesserung Grenzen zu haben, wenn es um die Fähigkeit zur chemischen Intuition oder zur Bewertung chemischer Präferenzen geht. Hier lagen die Modelle in ihren Vorhersagen oft nahe am Zufall und konnten die Präferenzen erfahrener Medicinalchemiker nicht zuverlässig nachbilden. Die ChemBench-Plattform erschafft hierbei einen wertvollen Rahmen, um systematisch chemische Fähigkeiten von KI-Systemen zu testen und lässt zudem den Vergleich mit menschlichen Experten zu. Interessanterweise zeigten sich die menschlichen Probanden in der Studie durchweg vom Leistungsniveau der KI beeindruckt, jedoch äußerten viele auch Bedenken hinsichtlich der gelegentlich fehlenden Zuverlässigkeit und der mangelnden Fähigkeit, Unsicherheiten realistisch einzuschätzen. Im Kontext der chemischen Ausbildung eröffnen diese Ergebnisse neue Perspektiven.
Die traditionelle Vermittlung von Faktenwissen allein wird durch KI-Systeme immer mehr relativiert, da sie solche Informationen oft schneller und fehlerfrei abrufen können. Wichtig wird daher die Schulung im kritischen Denken, dem Verstehen von Konzepten und der Interpretation von Daten. Die Rolle des Chemikers wandelt sich demnach zunehmend zu einem Experten, der KI richtig einsetzt, deren Ergebnisse hinterfragt und die kreative Integration von Wissen vorantreibt. Auch der Einsatz von KI als Copilot in der chemischen Forschung und im Labor gewinnt zunehmend an Bedeutung. Sprachmodelle können als Assistenten fungieren, die bei der Suche nach Literatur, der Auswertung komplexer Daten oder der Planung von Experimenten unterstützen.
Dabei ist jedoch eine enge menschliche Kontrolle unabdingbar, um Fehlinterpretationen und potenziell gefährliche Fehler zu vermeiden. Neben den technischen Herausforderungen wirft die Nutzung von LLMs in der Chemie auch ethische und sicherheitsbezogene Fragen auf. Es besteht die Gefahr, dass solche Modelle für die Entwicklung schädlicher Substanzen missbraucht werden könnten. Daher ist es wichtig, verantwortliche Nutzungskonzepte, Filtermechanismen und Monitoring-Strategien zu entwickeln, um dual-use Risiken zu minimieren. Die Zukunft der Chemie im Zeitalter der künstlichen Intelligenz wird somit durch eine enge Verzahnung von menschlichem Fachwissen und KI-Unterstützung geprägt sein.
Die Kombination der Fähigkeit von LLMs zur schnellen Verarbeitung und Aggregation großer Datenmengen mit der Kreativität, Erfahrung und kritischen Denkfähigkeit von Chemikern bietet enormes Potenzial. Regierungen, Forschungsinstitute und Unternehmen investieren bereits verstärkt in die Weiterentwicklung spezialisierter Chemie-Modelle sowie in deren Integration in digitale Laborumgebungen. Paradoxerweise zeigt die Analyse der ChemBench-Daten auch, dass die derzeitige Methodik zur Bewertung sowohl menschlicher als auch maschineller Chemiekenntnisse überdacht werden muss. Standardisierte Prüfungen und Multiple-Choice-Fragen können womöglich nicht mehr alle Facetten der Kompetenz widerspiegeln, vor allem da LLMs enorm große Datenquellen verarbeiten können. Neue Prüfungsformen, die komplexe Problemlösungsstrategien und logisches Denken einfordern, könnten gut geeignet sein, um zukünftige Chemiker adäquat zu bewerten.
Letztendlich zeugt der rasche Ausbau der Fähigkeiten großer Sprachmodelle im chemischen Bereich von einem bedeutenden technischen Fortschritt, der bereits jetzt das Potenzial hat, Forschung und Lehre deutlich zu verändern. Dennoch sind große Sprachmodelle keine Ersatz für menschliche Expertise, sondern kraftvolle Werkzeuge, deren Nutzen wesentlich von deren richtiger Anwendung und Integration abhängt. Die Chemie steht somit an einer spannenden Schnittstelle zwischen Tradition und Innovation, an der Bildung, Sicherheit und Vertrauenswürdigkeit stark gefragt sind. In einer Zeit, in der Daten und Informationen explosionsartig wachsen, stellen LLMs eine Schlüsseltechnologie dar, um dieses Wissen zugänglich und nutzbar zu machen. Chemiker profitieren von der Unterstützung bei Routinefragen und der Anregung kreativer Ideen.
Entsprechend darf man gespannt sein, wie sich diese Symbiose weiterentwickelt und welche neuen Horizonte sich für die chemische Wissenschaft und Industrie eröffnen werden.