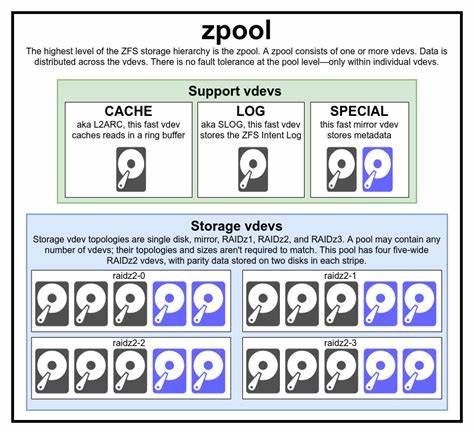
ZFS hat sich in den letzten Jahren als eines der fortschrittlichsten und robustesten Dateisysteme etabliert, die heute verfügbar sind. Ursprünglich von Sun Microsystems für Solaris entwickelt, wurde ZFS inzwischen in zahlreichen Betriebssystemen wie FreeBSD, Linux und MacOS integriert und überzeugt besonders durch seine einzigartige Architektur, die traditionelle Grenzen zwischen Volume-Management und Dateisystem auflöst. Das Ziel von ZFS ist es, Speicherverwaltung und Datenintegrität auf eine völlig neue Ebene zu heben, während gleichzeitig eine erstklassige Leistung gewährleistet wird. Ein Grundverständnis der Basiskomponenten von ZFS ist essenziell, um seine Speicher- und Performanceeigenschaften voll zu erfassen. An der Spitze steht der sogenannte zpool, der als Hauptbehälter für verschiedene virtuelle Geräte, kurz vdevs, fungiert.
Diese vdevs wiederum setzen sich aus einzelnen physischen oder logischen Geräten zusammen. Es ist wichtig zu wissen, dass die Redundanz von ZFS auf der Ebene der vdevs und nicht auf der des zpools organisiert ist. Das bedeutet, dass der Verlust eines vdevs einen Totalverlust des gesamten zpools zur Folge haben kann. ZFS verwendet verschiedene Arten von vdevs, darunter solche mit RAIDz1, RAIDz2 oder RAIDz3 Konfigurationen sowie Spiegelungen (Mirrors). RAIDz Varianten nutzen eine diagonal verteilte Parität, die es ermöglicht, einzelne oder mehrere Laufwerke innerhalb eines vdevs ausfalltolerant zu speichern.
Spiegel werden dadurch charakterisiert, dass Daten redundant auf mehreren Geräten gespeichert werden, was nicht nur die Ausfallsicherheit erhöht, sondern auch die Lesegeschwindigkeit verbessert, da Lesefragen parallel abgearbeitet werden können. Dagegen sind vdevs, die nur aus einem einzelnen Gerät bestehen, ein Risiko, da ein Ausfall sofort die Integrität des gesamten zpools bedroht. Ein weiterer besonderer Typ von vdev ist der sogenannte Cache- oder LOG-vdev. Ein LOG-vdev, auch SLOG genannt, ist speziell für die Optimierung synchroner Schreibvorgänge konzipiert. In einem herkömmlichen Dateisystem können synchronisierte Schreibvorgänge die Leistung deutlich beeinträchtigen, da sie sofort auf die physische Speicherung warten müssen.
ZFS leitet diese Schreibvorgänge vorübergehend in den ZFS Intent Log (ZIL) um, der entweder auf dem Hauptspeicher oder auf einem separaten, schnellen LOG-vdev abgelegt wird. Die Folge ist eine deutliche Reduzierung der Latenzen bei synchronen Schreibzugriffen, was insbesondere bei datenbanklastigen oder virtualisierten Umgebungen Vorteile bringt. At the core of ZFS’s robustness lies the Copy-on-Write (CoW) principle. This method ensures that existing data is never overwritten directly. Instead, modifications result in new blocks being written, and once these are committed, the pointers to the old blocks are updated.
This atomic operation guarantees filesystem consistency, even after crashes or power failures. The CoW mechanism also allows space-efficient snapshots and replication. Snapshots in ZFS are essentially read-only pointers to a specific point in time of the data pool, facilitating quick backups and rollbacks without duplicating actual data. Understanding the physical layer is key to optimizing a ZFS environment. Each physical storage device has a sector size, typically 512 bytes or 4 KiB.
ZFS translates this concept into the ‘ashift’ property, which defines the power of two for sector size (i.e., ashift=9 corresponds to 512 bytes, ashift=12 to 4096 bytes). Setting ashift correctly is critical because a mismatch can lead to severe performance degradation due to read-modify-write cycles. For example, writing 512-byte blocks on a device using 4 KiB sectors without proper ashift settings may cause multiple unnecessary I/O operations.
Despite the risks, setting ashift too high generally results only in marginal space inefficiencies, especially when compression is enabled. Speaking of compression, ZFS supports multiple inline compression algorithms such as LZ4, gzip, LZJB, and ZLE. LZ4 stands out due to its excellent balance between speed and compression ratio, often accelerating data transfer and storage throughput in typical scenarios. Compression not only saves physical space but also reduces I/O load, enhancing overall performance especially for data that compresses well. This makes it particularly useful for virtual machine images, databases, and text-heavy files.
The Adaptive Replacement Cache (ARC) forms ZFS’s intelligent second-level read cache and differentiates it from many conventional filesystems that rely solely on the operating system’s page cache. ARC’s algorithm combines recent and frequent access patterns to prioritize cached data better and reduce unnecessary evictions, resulting in a higher cache hit rate. By storing frequently read data in RAM, ARC minimizes disk I/O, significantly reducing latency and boosting read performance. Administratoren sollten außerdem die feinen Unterschiede zwischen synchronen und asynchronen Schreibvorgängen beachten. Asynchrone Schreibvorgänge werden in ZFS gebündelt und in Transaktionsgruppen verarbeitet, um die Effizienz zu steigern und Fragmentierung zu minimieren.
Synchrone Schreibvorgänge hingegen werden sofort in den ZIL (oder auf einem LOG-vdev) protokolliert, um die Integrität zu garantieren. Diese Unterscheidung ist für Workloads wie Datenbanken oder virtualisierte Umgebungen von großer Bedeutung, da sie die Performance stark beeinflusst. ZFS erleichtert zudem die Replikation von Daten durch seine Snapshot-Technologie. Statt ganze Datenbestände bei jeder Sicherung erneut zu übertragen, sendet ZFS mittels snapshots nur die Veränderungen zwischen zwei Zeitpunkten. Diese inkrementelle Abfrage spart Bandbreite und Zeit und ermöglicht eine effiziente Datensicherung und Klonung.
In Vergleichen zeigt ZFS Replikation teilweise Performancevorteile von hunderten bis tausenden Prozent gegenüber traditionellen Methoden wie rsync. Für Nutzer, die eine Speicherlösung planen oder bestehende ZFS Pools optimieren möchten, sind einige zentrale Empfehlungen zu beachten. Die Wahl der richtigen vdev-Topologie hängt vom angestrebten Gleichgewicht zwischen Kapazität, Ausfallsicherheit und Leistung ab. RAIDz2 bietet eine solide Balance für die Mehrheit der Anwendungsfälle, während Spiegelungen vor allem bei hoher Last und Bedarf an schneller Leseleistung bevorzugt werden. Ebenso ist es ratsam, die Verwendung von gemischten Laufwerken in einem Pool zu vermeiden, da die Leistung grundsätzlich vom langsamsten Gerät limitiert wird.
Außerdem ist es unerlässlich, vor der Einrichtung den sector size Wert (ashift) korrekt einzustellen, um beim Aufbau von Pools langfristige Performanceeinbußen zu vermeiden. Supportvdev Typen wie LOG und CACHE können gezielt zur Beschleunigung synchroner Schreibvorgänge und häufig gelesener Daten eingesetzt werden. Bei besonderen Anforderungen an Wear-Leveling und Langlebigkeit von SSDs unterstützt ZFS zudem die Verwendung von Special Allocation vdevs. Abschließend lässt sich sagen, dass ZFS mit seinem ganzheitlichen Konzept aus Datensicherheit, Flexibilität und Performance eine Technologie ist, die trotz ihrer Komplexität einen großen Mehrwert in heterogenen IT-Umgebungen bieten kann. Die tiefergehende Kenntnis insbesondere der Zusammenhänge von zpools, vdevs, Geräten und den Speichermechanismen ist für jeden Administrator oder Technikbegeisterten unverzichtbar, der das Ersatzdatenmanagement der Zukunft sehen möchte.
Wer sich intensiv mit ZFS auseinandersetzt, wird schnell entdecken, dass die „einfachen“ Grundlagen lediglich der Anfang eines umfassenden Spektrums von Möglichkeiten sind. Von Performancetuning über erweiterte Redundanzkonzepte bis hin zu komplexen Replikationsstrategien reicht die Palette. Die Investition in Wissen und Verständnis zahlt sich durch eine deutlich erhöhte Ausfallsicherheit, Datenintegrität und eine nachhaltige Systemleistung aus. Somit ist ZFS weit mehr als nur ein modernes Dateisystem – es ist ein grundlegend neuer Ansatz für Storage Management in einer zunehmend datengetriebenen Welt.