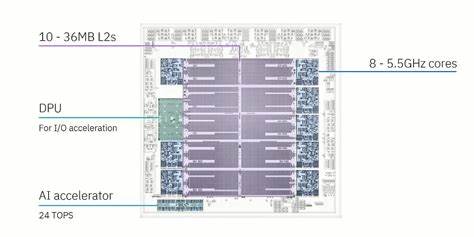
Mainframes sind trotz des Trends zu verteilten Cloud-Systemen und nachhaltiger Virtualisierung nach wie vor eine tragende Säule der IT-Infrastruktur, insbesondere im Finanzsektor, der auf höchste Ausfallsicherheit und minimale Latenzzeiten angewiesen ist. IBM unterstreicht diese Rolle mit seinem neuesten Prozessordesign Telum II, das auf der Hot Chips-Konferenz 2024 vorgestellt wurde. Telum II verbindet klassische Mainframe-Qualitäten mit innovativen Ansätzen, um den steigenden Anforderungen an Performance und Effizienz gerecht zu werden. Ein herausragendes Merkmal von Telum II ist die einzigartige Caching-Strategie, die sich grundlegend vom konventionellen Serverprozessor-Design unterscheidet. Statt einer hohen Kernzahl setzt IBM auf acht sehr schnelle Kerne mit 5,5 GHz, die durch einen riesigen On-Chip-Cache von 360 MB unterstützt werden – ein außergewöhnliches Volumen für Serverprozessoren.
Dieser massive Cache spielt eine zentrale Rolle, um die physikalischen Grenzen der DRAM-Zugriffe zu kompensieren. Die Grenzen bei Latenzen und Bandbreiten in der Hauptspeicherkommunikation stellen für die Performance heutiger CPUs eine der größten Herausforderungen dar. Telum II setzt hier an, indem der Cache nicht nur riesig, sondern auch innovativ organisiert ist. Im Kern steht ein Konzept virtueller Cache-Ebenen, das bereits bei Vorgängergenerationen von IBM angewandt wurde, nun aber noch konsequenter weiterentwickelt wurde. Grundlegend besitzt jeder der acht Kerne einen eigenen 36 MB großen L2-Cache, der im Vergleich zu vielen Desktop- und Server-CPUs extrem groß ist.
Zum Vergleich: AMDs Zen 3 Architektur verwendet typischerweise 32 MB L3-Cache für mehrere Kerne gemeinsam. Zusätzlich erhalten der Data Processing Unit (DPU) und ein weiterer Cache-Slice, der keinem Kern zugeordnet ist, ebenfalls jeweils 36 MB L2-Cache. Somit stehen zehn dieser riesigen Cache-Slices zur Verfügung. Um die enormen SRAM-Kosten eines herkömmlichen, großen L3-Caches zu vermeiden, nutzt IBM ein ausgeklügeltes System der Cache-Kohärenz und -Reorganisation. Das Prinzip basiert darauf, Daten, die in einem L2-Cache nicht mehr gehalten werden können – sogenannte „Evictions“ – intelligent an andere L2-Slices weiterzugeben.
Dabei wird auf sogenannte „Saturation Metrics“ zurückgegriffen, eine Art Bewertung, die misst, wie sehr ein Cache-Slice ausgelastet ist. Cache-Linien, die von einem Kern nicht mehr gehalten werden können, wandern in die L2-Caches mit einer niedrigeren Auslastung, statt direkten Verlust zu erleiden. Diese Umverteilung schafft effektiv eine „virtuelle L3“, die die Vorteile eines großen gemeinsamen Caches simuliert und dabei trotzdem auf die bestehende L2-Struktur setzt und zugleich Daten-Duplikationen reduziert. Ein weiterer Trick in der Ersetzungspolitik ist die Einordnung der sogenannten virtuellen L3-Daten in mittlere Positionen der „Least Recently Used“-Reihenfolge, was verhindert, dass „virtuelle“ Cache-Daten die Kapazität eigentlich aktiv genutzter Caches verdrängen. So ist sichergestellt, dass die Kerne stets schnellen Zugriff auf ihre wichtigsten Daten haben, während gleichzeitig der Gesamtspeicher besser ausgelastet wird.
Dieses ausgeklügelte Balancing wirkt sich besonders auf die Single-Thread-Leistung positiv aus, ein Bereich, in dem Mainframe-CPUs traditionell stark sein müssen. Ein weiteres Innovationselement in der Architektur ist der sogenannte virtuelle L4-Cache, der über mehrere Telum-II-Prozessoren hinweg implementiert wird. IBM ermöglicht damit eine Cache-Kohärenz im großen Maßstab, indem L3-Kandidaten, die aus einem Kerns Cache ausgestoßen werden, in anderen Prozessoren verwahrt werden. Diese Umsetzung scheint über das physische „Central Processor Complex“ (CPC) Drawer Konzept realisiert zu sein, in dem mehrere Prozessor-Dies mit direkter Anbindung an gemeinsamen Hauptspeicher und Cache zusammenarbeiten. IBM gibt an, dass der virtuelle L4-Cache rund 2,8 GB umfasst, was die einmalige Größe und Komplexität des Caching über eine Drawer-Architektur hinweg unterstreicht.
Latenztechnisch bewegt sich ein L4-Zugriff mit circa 48,5 Nanosekunden überraschend unter den Erwartungen für ein solch verteiltes System und demonstriert die Fortschritte bei geteilten Speicherarchitekturen in Mainframes. Der Weg, den IBM mit Telum II geht, hebt die klassische Dichotomie zwischen Single- und Multithread-Leistung auf. Moderne Client-Prozessoren optimieren meist für hochgradige Parallelität, während Mainframes traditionell Wert auf deterministische, extrem schnelle Einzelthreadausführungen legen. Mit Telum II schrumpft die Kernanzahl von 12 (im Vorgänger Z15) auf 8, dafür aber mit einem beeindruckenden Takt von 5,5 GHz, der im Zusammenspiel mit dem voluminösen Cache für Szenarien wie Finanztransaktionen und Echtzeit-Analysen optimal ist. Neben den außergewöhnlichen Caches investiert IBM auch in spezielle Hardware-Beschleuniger.
So ersetzt Telum II den bisherigen System Controller teilweise durch einen auf dem Chip integrierten Data Processing Unit (DPU), der die Ein- und Ausgabe beschleunigt und Lastspitzen abfedert. Zudem ist ein KI-Beschleuniger an Bord, der speziell für maschinelles Lernen bei der Datenanalyse oder Betrugserkennung entwickelt wurde. Die Fertigung des Prozessors auf einem fortschrittlichen 5-Nanometer-Prozess von Samsung sichert dabei eine günstige Energieeffizienz trotz hoher Taktfrequenzen und hoher Komplexität. Im Vergleich zu anderen High-End-CPUs fällt das Design des Telum II durch seine radikale Cache-Philosophie und die Konzentration auf Single-Core-Performance auf. Während beispielsweise AMDs Zen-5-Kerne mit deutlich weniger L2-Cache auskommen und auf eine größere und schnellere L3-Ebene in Form eines gemeinsamen Caches setzen, verfolgt IBM einen anderen Ansatz: enorme lokale Cachegrößen, kombiniert mit einem „virtuellen“ Höherlegen der Cache-Hierarchie.
Dies ist möglich, weil die Hauptaufgabe von Mainframes oft nicht extrem parallele Lasten, sondern latenzkritische, einzelthreadige Zugriffe auf große Datensätze umfasst. Wichtig ist zudem, dass im Vergleich zu Consumer-Produkten IBM eigenen Angaben zufolge weit höhere Datenbandbreite und geringere Latenzzeiten beim Cross-Die-Datenaustausch erreicht – ein Resultat aus den speziell entwickelten Interconnect-Technologien und einer ausgeklügelten Systemarchitektur. Die Frage, ob solch eine innovative Architektur auch im Client-Bereich anwendbar ist, bleibt spannend. Hersteller wie AMD experimentieren etwa mit „VCache“ und profitieren ebenfalls von großen Cachevolumina für Performance-Gewinne in Cache-sensitiven Anwendungen wie Spielen. Doch die aufwendige und kostenintensive Verpackungstechnologie, die IBM für den Telum II einsetzt, könnte sich für den Endverbrauchermarkt als zu teuer erweisen.
Dennoch zeigt IBM mit Telum II eindrucksvoll, wie sich langfristig durch Investitionen in intelligente Cache-Architekturen und Co-Packaging-Technologien signifikante Leistungssteigerungen erzielen lassen. Insgesamt ist Telum II ein Paradebeispiel dafür, wie Mainframe-Hersteller weiterhin mit innovativen Ideen die Grenzen der Prozessor-Performance verschieben. Die Mischung aus großen On-Chip Caches, virtuellen Cache-Ebenen und spezieller Beschleuniger-Hardware demonstriert, dass traditionelle Systeme keineswegs antiquiert sind, sondern im Gegenteil neue Trends setzen. Hot Chips 2024 stellt mit der Präsentation von Telum II unter Beweis, dass es bei der Entwicklung von Hochleistungsrechnern heute weniger um reine Kernzahlen geht, sondern um intelligente Ressourcennutzung und Latenzoptimierung auf komplexer Ebene. In einer Welt, die immer schnellere und zuverlässigere IT-Infrastrukturen verlangt, ist Telum II ein wegweisender Schritt und trifft genau den Nerv der Zeit.
Die weiterhin hohe Bedeutung von Mainframes, gepaart mit modernen Halbleitertechnologien und neuartigen Architekturen, sichert IBM eine Schlüsselrolle in der Zukunft leistungsfähiger Serverplattformen.