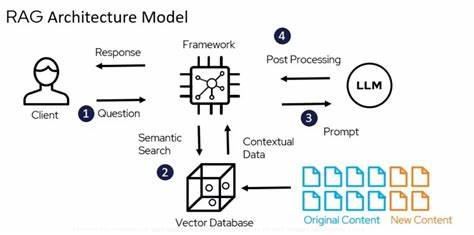
Die rasante Entwicklung im Bereich der Künstlichen Intelligenz (KI) und insbesondere der Large Language Models (LLMs) hat das Potenzial, die Art und Weise, wie wir mit Information umgehen, grundlegend zu verändern. Besonders vielversprechend ist die Kombination von generativen Modellen mit präzisen Methoden der Informationsretrievals, welche unter dem Begriff Retrieval Augmented Generation (RAG) zusammengefasst wird. Ein aktueller Erfahrungsbericht aus dem Jahr 2024 widmet sich der Nutzung von PDFs als Hauptdatenquelle, um RAG-Systeme zu entwickeln und so eine Brücke zwischen unstrukturierten Dokumenten und interaktiver Wissensverarbeitung zu schlagen. Dieses Thema gewinnt besonders für Unternehmen, akademische Einrichtungen und Forschungsprojekte an Bedeutung, da ein Großteil der existierenden Informationen in Form von PDFs vorliegt, die schwer automatisiert auswertbar sind. Die Grundlage von RAG-Systemen besteht darin, die generativen Fähigkeiten von LLMs nahtlos mit den Stärken von Retrieval-Methoden zu verbinden.
Während LLMs exzellente sprachliche und inhaltliche Zusammenfassungen oder Antworten generieren können, fehlt ihnen oft der genaue Zugriff auf aktuellere, domänenspezifische oder strukturierte Daten. Indem sie jedoch Informationen gezielt aus einer vorher abgefragten Wissensbasis abrufen, können RAG-Systeme die Genauigkeit und Kontextspezifität ihrer Antworten erheblich verbessern. Im Fokus des besprochenen Berichts stehen dabei zwei technologische Ansätze: Zum einen der Einsatz von OpenAI’s Assistant API mit GPT-Modellen, zum anderen die Nutzung von Llamas Open-Source-Modellen. Beide Wege bieten einzigartige Chancen und Herausforderungen, die es zu verstehen gilt, um robuste, anpassbare und skalierbare Systeme zu bauen. Ein zentraler Aspekt der Umsetzung besteht in der Datenverarbeitung.
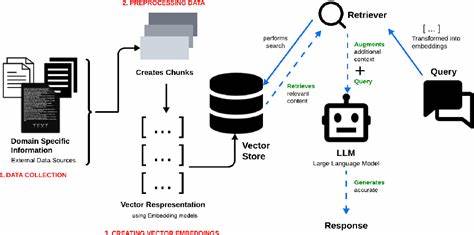
PDFs sind bekanntlich ein anspruchsvolles Format für automatische Textverarbeitung, da sie nicht primär für maschinelle Auswertungen optimiert sind. Der Bericht beschreibt ausführlich, wie der gesamte Datenverarbeitungs-Pipeline gestaltet wurde: Beginnend bei der Datensammlung über die Bereinigung und strukturelle Aufbereitung bis hin zur Indizierung und schließlich dem Retrieval der relevanten Textteile für die Antwortgenerierung. Besonders spannend sind die technischen Herausforderungen, wie zum Beispiel die Extraktion von Text aus komplex formatierten PDFs, die Bewältigung unterschiedlicher Layouts, Tabellen und Grafiken sowie die Handhabung von multisprachigen Dokumenten. Ein weiterer wichtiger Punkt ist die Erstellung effizienter Retrieval-Indizes, die eine schnelle und zugleich relevante Suche ermöglichen. Hierbei wurde mit verschiedenen Ansätzen experimentiert, um eine Balance zwischen Performanz und Präzision zu finden.
Die Verwendung moderner Vektor-Datenbanken und Embedding-Technologien macht es möglich, semantische Ähnlichkeit zwischen Suchanfragen und Dokumentinhalten herzustellen, was klassische Suchmaschinen oft nicht leisten können. Durch diesen Ansatz gelingt es, selbst komplexe oder kontextabhängige Nutzeranfragen mit einer höheren Treffergenauigkeit zu beantworten. Besonderes Augenmerk legt der Bericht auch auf die Integration der Retrieval-Komponente mit den generativen Modellen. Statt die LLMs alleine mit der Rohinformation der PDFs zu füttern, werden ihnen passgenaue, relevante Ausschnitte zur Verfügung gestellt, welche die Qualität der generierten Antworten deutlich verbessern. Dies reduziert nicht nur Halluzinationen (also die fehlerhafte Erfindung von Fakten durch das Modell), sondern erhöht auch die Transparenz des Systems, da nachvollziehbar bleibt, aus welchen Quellen die Informationen stammen.
Die Kombination aus präziser Informationsentnahme und kreativer Textgenerierung eröffnet neue Anwendungsgebiete und steigert die Verlässlichkeit generativer KI-Systeme in kritischen Bereichen. Der Erfahrungsbericht hebt zudem die praktischen Implikationen hervor. In Branchen wie dem Rechtswesen, der Medizin oder der Wissenschaft, wo es auf aktuelle und präzise Informationen ankommt, können solche RAG-basierten Systeme enorme Effizienzgewinne bringen. Die zeitaufwändige manuelle Durchsicht umfangreicher Dokumentenmengen kann automatisiert und zugleich qualitativ hochwertig unterstützt werden. Insbesondere die Möglichkeit, sich direkt aus PDF-Dokumenten präzise Antworten generieren zu lassen, erlaubt Anwendern eine neue Form der Interaktion mit Wissen – weg von starren Datenbanken hin zu dynamischen und kontextsensitiven Informationssystemen.
Bemerkenswert ist auch der offene Zugang zum verwendeten Python-Code des Projekts. Dies ermöglicht Forschungsteams und Entwicklerinnen, eigene Projekte auf der Basis der erprobten Pipeline weiterzuentwickeln und an individuelle Anforderungen anzupassen. Die offene Softwarepraxis fördert zudem den Austausch von Ideen und Best Practices in der wachsenden Community, die sich mit Retrieval Augmented Generation und Large Language Models beschäftigt. Der Bericht macht deutlich, dass trotz der großen Fortschritte weiterhin Herausforderungen bestehen. Dazu zählen insbesondere die Verbesserung der Extraktionstechnik von PDFs mit komplexen Layouts, die effiziente Skalierung der Retrieval-Methoden bei riesigen Dokumentensammlungen sowie die Minimierung unerwünschter Verzerrungen in den generierten Antworten.
Auch die ethischen Fragestellungen rund um Transparenz, Datenschutz und Verantwortung im Umgang mit generativer KI bleiben wichtige Themen, die parallel zur technischen Entwicklung adressiert werden müssen. Zusammenfassend zeigt der Erfahrungsbericht zur Entwicklung von RAG-basierten LLM-Systemen aus PDFs eindrucksvoll, wie die Kombination von Informationsretrieval und generativer KI die Zukunft der Wissensverarbeitung gestalten kann. Das Zusammenspiel von präziser Datenaufbereitung, intelligentem indexing und innovativen generativen Modellen erschließt vielfältige Anwendungsmöglichkeiten, die von verbesserten Recherchetools bis hin zu unterstützenden Assistenzsystemen reichen. Durch die Veröffentlichung der Ergebnisse und des Codes leistet die Arbeit zudem einen wertvollen Beitrag zur Demokratisierung von KI-Technologien und legt den Grundstein für weiterführende Innovationen in diesem zukunftsträchtigen Forschungsfeld. Die Rolle von PDFs als Informationsquelle wird auch künftig eine große Bedeutung behalten, insbesondere da viele offizielle Dokumente, wissenschaftliche Publikationen oder technische Handbücher nach wie vor vorwiegend in diesem Format vorliegen.
Die Entwicklung spezialisierter RAG-Systeme, die genau auf dieses Datenformat zugeschnitten sind, verspricht daher nachhaltige Verbesserungen in der Art und Weise, wie Wissen gespeichert, aufgefunden und genutzt wird. Für Entwickler, Forscher und Anwender ist dies eine spannende Gelegenheit, die Möglichkeiten der KI gezielt zu nutzen und so neue Standards im Information Management zu setzen.