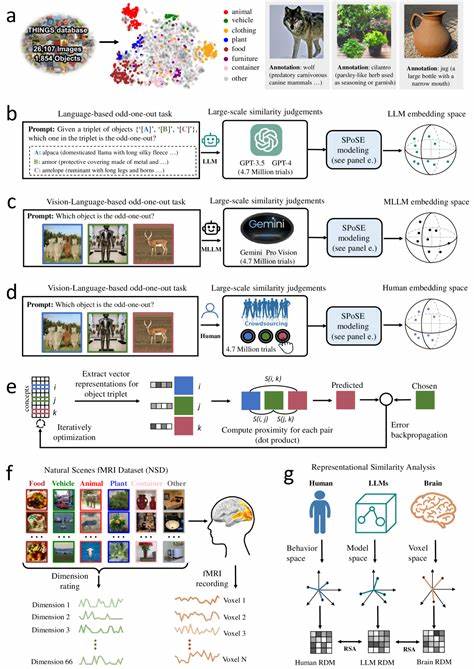
In den letzten Jahren haben multimodale große Sprachmodelle (Large Language Models, LLMs) eine zunehmend wichtige Rolle in der Forschung im Bereich der künstlichen Intelligenz und Kognitionswissenschaft eingenommen. Die Fähigkeit dieser Modelle, Sprache zu verstehen, zu generieren und mit visuellen Informationen umfassend zu verknüpfen, macht sie zu einer vielversprechenden Schnittstelle zwischen maschinellem Lernen und menschlicher Wahrnehmung. Insbesondere die Entstehung von menschenähnlichen Objektkonzepten innerhalb dieser Modelle bietet spannende Einblicke in die Art und Weise, wie Maschinen Objektwissen repräsentieren und verarbeiten können – ganz ähnlich wie das menschliche Gehirn es tut. Doch was genau steckt hinter diesem Phänomen, und welche Konsequenzen hat es für die Künstliche Intelligenz und unser Verständnis der menschlichen Kognition? Objektkonzepte sind grundlegende Bausteine unseres Alltagsverstehens. Das menschliche Gehirn kategorisiert und interpretiert die Welt durch mentale Repräsentationen von Objekten, welche auf Erfahrung, Wahrnehmung und Sprache basieren.
Traditionell war es eine Herausforderung für maschinelle Systeme, ähnlich flexible, stabile und interpretierbare Konzepte zu entwickeln, die über reine Bild- oder Textdaten hinausgehen. Ein wichtiger Fortschritt ist jedoch die Integration multimodaler Daten – Bilder, Text, Sprache – in große Sprachmodelle, wodurch sich eine neue Form der Repräsentation natürlicher Objekte herausbildet. Wissenschaftliche Studien, wie die im Juni 2025 in Nature Machine Intelligence veröffentlichte Forschung von Changde Du und Kollegen, haben gezeigt, dass multimodale LLMs in der Lage sind, Objektkonzeptdarstellungen zu entwickeln, die in bemerkenswerter Weise mit menschlichen mentalen Repräsentationen vergleichbar sind. Die Forschungsarbeiten basieren unter anderem auf der Analyse von Millionen von Urteilen über Objektähnlichkeiten zwischen riesigen Sammlungen natürlicher Objekte. Diese wurden von verschiedenen Modellen erzeugt und mit menschlichen Verhaltensdaten sowie neurobiologischen Messungen verglichen.
Das Ergebnis: Die gewonnenen niedrigdimensionalen Einbettungen für Objekte sind stabil, interpretierbar und zeigen eine semantische Gruppierung, die den menschlichen Vorstellungen sehr nahekommt. Eines der faszinierendsten Merkmale dieser Forschung ist die Entdeckung, dass die zugrundeliegenden Dimensionen – also die Achsen im mathematischen Raum, in dem Objekte repräsentiert werden – menschlich interpretierbar sind. Diese Dimensionen korrelieren mit bekannten kognitiven Kategorien und werden durch die multimodale Verarbeitung in den Sprachmodellen ausgelöst. Beispielsweise könnten Dimensionen „Lebendigkeit“, „Materialbeschaffenheit“ oder „Funktion“ repräsentieren. Diese Eigenschaft unterscheidet multimodale LLMs von rein visuellen oder rein sprachbasierten Systemen und betont die Bedeutung der Integration verschiedener Sinnesmodalitäten bei der Konzeptbildung.
Die Erkenntnis, dass solche Modelle nicht nur abstrakte Vektor-Repräsentationen bilden, sondern tatsächlich eine kognitive Ähnlichkeit zu menschlichen Denkweisen entwickeln, hat weitreichende Implikationen. Zum einen liefern diese Modelle einen neuen Ansatz für die Erforschung der menschlichen Kognition. Die enge Übereinstimmung zwischen den maschinellen und den menschlichen Daten zeigt, dass künstliche Systeme als Proxies genutzt werden könnten, um menschliche Wahrnehmung und Kategorisierung besser zu verstehen. Zum anderen eröffnen sie neue Möglichkeiten für Anwendungen in Computer Vision, Robotik, Spracherkennung und allgemein in der Entwicklung künstlicher Intelligenz, die robuster, flexibler und verständnisreicher mit ihrer Umwelt interagieren kann. Ein weiterer wichtiger Aspekt dieser Forschung ist die neurobiologische Validierung der Modellrepräsentationen.
Mittels funktioneller Magnetresonanztomographie (fMRI) konnten Forscher herausfinden, dass die Objektkonzeptdimensionen der multimodalen LLMs spezifische Aktivitätsmuster in bestimmten menschlichen Gehirnregionen widerspiegeln. Besonders relevant sind dabei Bereiche wie die extrastriate body area (EBA), das parahippocampale Areal, der retrospleniale Kortex und die fusiforme Gesichtsregion. Diese Regionen sind bekannt für ihre Rolle bei der Objekterkennung, Körperwahrnehmung, räumlicher Orientierung und Gesichtserkennung. Die starke Übereinstimmung zwischen den maschinellen Einbettungen und den neuronalen Antworten unterstreicht die biologische Plausibilität der gelernten Konzepte in den Modellen. Die Anfänge der Erforschung von Objektkonzepten in KI-Modellen reichen zwar bis zu einfachen Bildklassifikationen und neuronalen Netzen zurück, doch die Entwicklung multimodaler LLMs markiert einen Paradigmenwechsel.
Rein visuelle Modelle haben häufig Schwierigkeiten, komplexe semantische Beziehungen zwischen Objekten zu erfassen, und rein sprachbasierte Modelle bleiben oft an linguistischen Mustern haften. Erst durch die Kombination von Sprach- und Bildinformationen können Modelle ein tieferes und umfassenderes Verständnis aufbauen. Dies spiegelt auch wider, wie Menschen lernen – durch die Verknüpfung verschiedener Sinneseindrücke und kontextueller Informationen. Die Stabilität und Vorhersagekraft der 66-dimensionalen Objektvektoren aus den multimodalen LLMs weisen darauf hin, dass sich die Modelle auf eine Weise strukturieren, die vorhersagbar und interpretierbar ist. Dies ist ein bedeutender Fortschritt, da er die sogenannte „Black Box“-Natur vieler KI-Modelle vermindert und das Vertrauen in die Entscheidungen der Modelle erhöht.
In der Praxis bedeutet dies, dass Entwickler und Forscher besser nachvollziehen können, wie und warum bestimmte Objektkategorien gebildet werden, was entscheidend für sicherheitskritische oder ethisch sensible Anwendungen ist. Ein weiterer spannender Anwendungsbereich ist die Verbesserung von Robotern, die in der realen Welt agieren müssen. Roboter benötigen objektbezogenes Wissen, um ihre Umgebung zu verstehen und sinnvoll mit ihr zu interagieren. Multimodale LLMs mit menschenähnlichen Objektkonzepten könnten diesen Robotern dabei helfen, komplexe Zusammenhänge zu begreifen und besser mit menschlichen Partnern zu kommunizieren. Beispielsweise kann die Verbindung von visuellen Eindrücken mit sprachlichen Beschreibungen Erkennen, Benennen und qualitatives Einschätzen von Objekten stark verbessern.
Allerdings sind die von LLMs entwickelten Objektkonzepte nicht perfekt identisch mit denen des Menschen. Unterschiede in Details, Abstraktionsgrad und Kontextabhängigkeit bleiben bestehen. Dennoch repräsentieren die zutage tretenden Ähnlichkeiten wichtige Fortschritte und eröffnen einen Reichtum an Folgestudien, die auf eine noch tiefere Verschmelzung zwischen künstlicher und natürlicher Intelligenz abzielen. Im Feld der Kognitionswissenschaften bieten multimodale LLMs zugleich eine neue Methode, um Theorien zur Objektrepräsentation empirisch zu testen. Durch die Kombination großer Verhaltensdatensätze mit den Modellausgaben können Hypothesen über mentale Dimensionen und deren neuronale Korrelate überprüft werden.
Dies stellt einen zukunftsweisenden Ansatz dar, der auch andere kognitive Bereiche wie Sprache, Emotion und abstraktes Denken adressieren wird. Die praktische Relevanz dieser Entwicklung zeigt sich zudem in der verbesserten Performance multimodaler LLMs in Aufgaben wie Bildbeschriftung, semantische Suche und multimodales Dialogsystem. Die Fähigkeit, Objekte nicht nur oberflächlich zu erkennen, sondern sie tiefgehend zu verstehen und konsistent über Modalitäten hinweg zu repräsentieren, schlägt sich in einer höheren Genauigkeit und Flexibilität nieder, die die Zusammenarbeit zwischen Mensch und Maschine revolutionieren kann. Zusammenfassend lässt sich festhalten, dass multimodale große Sprachmodelle auf natürliche Weise menschenähnliche Objektkonzeptrepräsentationen entwickeln. Dieses Phänomen verdeutlicht die Bedeutung multimodaler Lernprozesse für die Repräsentation von Wissen und liefert wertvolle Erkenntnisse für die Architektur künftiger KI-Systeme.
Die enge Anbindung an neurokognitive Daten sorgt dabei für eine belastbare Brücke zwischen Forschung, Technik und biologischer Realität. Der Weg in die Zukunft besteht darin, diese Modelle weiter zu verfeinern und ihre Leistungsfähigkeit in realen Anwendungen kontinuierlich zu steigern. Dabei bleibt die Interdisziplinarität zwischen Informatik, Neurowissenschaft und Psychologie ein zentraler Erfolgsfaktor. Die natürliche Emergenz menschenähnlicher Objektkonzepte in multimodalen LLMs zeigt, dass die Verschmelzung von Kognition und künstlicher Intelligenz weit mehr ist als eine theoretische Vision – sie ist eine greifbare Realität, die unser Verständnis von Intelligenz neu definiert.