In den letzten Jahren hat sich die Landschaft der künstlichen Intelligenz rasant weiterentwickelt. KI-Agenten sind längst nicht mehr simple Chatbots, sondern komplexe, autonome Systeme, die eigenständig Entscheidungen treffen, planen und auf verschiedenste Situationen reagieren können. Doch während sich die Fähigkeiten dieser Agenten vervielfachen, stellt sich eine spannende Frage: Wie lassen sich moderne KI-Agenten effizienter und skalierbarer entwickeln? Eine vielversprechende Antwort darauf ist die Nutzung von Streaming-SQL-Abfragen als Grundlage für die Implementierung solcher Agenten. Der Ursprung dieser Idee geht auf die Überlegung zurück, dass viele Dienste und Anwendungen, die wir heute als eigenständige Microservices betrachten, oft Aufgaben erfüllen, die sich in Form einer SQL-Abfrage auf einem Datenstrom elegant und präzise umsetzen lassen. Seth Wiesman hat mit seinem Vortrag „OH: That microservice should have been a SQL query“ auf der Kafka Summit darauf hingewiesen, dass Microservices als SQL Queries auf Streaming-Plattformen wie Apache Kafka oder Apache Flink schneller entwickelt, konsistenter betrieben und hoch skalierbar sind.
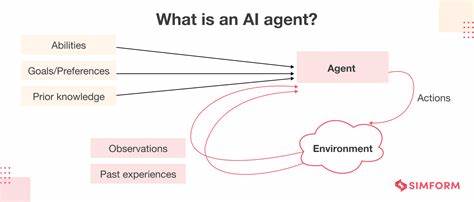
Diese Erkenntnis lässt sich auf KI-Agenten übertragen, die ebenfalls produktiv auf kontinuierliche Datenströme reagieren müssen. Ein KI-Agent ist im Kern ein Software-System, das auf Basis von künstlicher Intelligenz Ziele verfolgt und Aufgaben für Benutzer oder Systeme autonom erledigt. Typischerweise zählen dazu Fähigkeiten wie Planen, logisches Denken und Gedächtnis. Auch wenn manche Visionen von KI-Agenten an Science-Fiction erinnern, etwa die vollständige Automatisierung komplexer Geschäftsentscheidungen, sind die meisten produktiven Agenten heute gezielt als klar definierte, KI-unterstützte Workflows angelegt. Sie verarbeiten beispielsweise Kundenanfragen, analysieren Dokumente oder steuern automatisierte Verkaufs- und Wartungsprozesse.
Streaming-SQL bietet dabei eine neue Perspektive auf die Konstruktion solcher KI-Agenten. Im Gegensatz zu herkömmlichen SQL-Abfragen, die auf Pull-basierten Datenzugriff setzen und ihre Ergebnisse auf Anfrage liefern, arbeiten Streaming-SQL-Systeme kontinuierlich, mit Push-Mechanismus. Veränderungen in den Daten lösen unmittelbar Berechnungen aus und liefern inkrementelle Ergebnisse. Apache Flink ist hierfür eine führende Plattform, die sich hervorragend für den Aufbau eventgetriebener Anwendungen eignet und gleichzeitig hohe Performance, Ausfallsicherheit sowie Skalierbarkeit bereitstellt. Besonders spannend ist, dass Streaming-SQL-Engines wie Flink die Integration von großen Sprachmodellen (Large Language Models, LLMs) und anderen KI-Modellen unterstützen.
Über neue Erweiterungen können LLMs als erste Bürger in SQL definiert und genutzt werden, etwa mittels spezieller CREATE MODEL-Anweisungen. Dadurch können natürliche Sprachverarbeitung, Textzusammenfassungen, Sentiment-Analysen oder andere KI-basierte Aufgaben direkt innerhalb eines Streaming-SQL-Jobs ausgeführt werden. Ein praktisches Beispiel verdeutlicht dies: Forscher und Entwickler, die täglich Wissenschaftspublikationen sichten müssen, können mithilfe eines Streaming-SQL-Agenten neue Papers automatisch zusammenfassen lassen. Dabei wird der Text der Paper zunächst in einem Cloud-Speicher abgelegt und per Connector in Kafka eingespeist. Ein SQL-Job mit LLM-Integration erzeugt daraus Zusammenfassungen, Titel und Autorendaten und schreibt die Ergebnisse zurück in einen Kafka-Topic, was wiederum andere Systeme oder Benachrichtigungen auslösen kann.
So entsteht ein durchgängiger, automatisierter Workflow auf Datenstrombasis. Ein weiterer Vorteil von Streaming-SQL-basierten Agenten ist ihre intrinsische Event-Driven-Architektur. Während viele KI-Anwendungen heute auf synchrone Anfrage-Antwort-Kommunikation beruhen, sind vor allem im Enterprise-Umfeld autonome, asynchrone Agenten gefragt, die auf eingehende Ereignisse reagieren und selbstständig Aktionen auslösen. Flink und ähnliche Plattformen ermöglichen eine nahtlose Integration unterschiedlichster Datenquellen, von Benutzerinteraktionen über Sensordaten bis zu Datenbankänderungen. Das bedeutet, KI-Agenten können in Echtzeit auf veränderte Umgebungsbedingungen reagieren – sei es die automatische Nachbestellung im Lager oder die Erstellung von Wartungsaufträgen bei Maschinendaten.
Kontext und Gedächtnis sind weitere wesentliche Komponenten, die KI-Agenten benötigen, um effektiv zu arbeiten. Hier eröffnet Streaming-SQL durch Funktionen wie Joins und Look-up-Tabellen Möglichkeiten zur Anreicherung von Event-Daten mit externen Kontextinformationen, etwa Kundendaten aus CRMs oder Wissensdaten aus Dokumenten. Für unstrukturierte Daten kommen retrieval-augmented generation (RAG) Ansätze zum Einsatz, bei denen relevante Informationen aus Vektor-Datenbanken oder Indizes eingebunden und so den LLM-Prompts zusätzliches Domänenwissen geliefert wird. In Flink wird dies durch die Unterstützung von Vektor-Datentypen und User-Defined Functions (UDFs) ermöglicht. Mit der Einführung von Process Table Functions (PTF) hat Flink zudem einen Mechanismus implementiert, der eine flexible Verwaltung des Agentengedächtnisses erlaubt.
PTFs können Zustand über längere Zeiträume speichern und auf Teilströme angewandt werden, wodurch bisherige Ereignisse und Antworten eingesehen und für die Entscheidungsfindung genutzt werden können. So werden langlaufende kontextbasierte Workflows realisierbar, die der Funktionsweise von Gedächtnis in intelligenten Agenten nahekommen. Trotz all dieser Vorteile ist klar, dass Streaming-SQL nicht jede Herausforderung eines KI-Agenten abdeckt. Komplexere Entscheidungslogiken oder spezielle Integrationen externer Dienste erfordern oftmals direktes Programmieren oder das Hinzuziehen spezialisierter Frameworks. Die geplante Erweiterung „Flink Agents“ zielt darauf ab, eine spezielle Runtime zu schaffen, die die Stärken von Flink mit flexiblem Agenten-Management und Multi-Tool-Integration kombiniert.
Dabei soll durch die Unterstützung von Python auch der Zugriff auf eine reiche Bibliothekswelt an KI-Werkzeugen ermöglicht werden. In der Summe zeigt sich, dass Streaming-SQL als Paradigma für KI-Agenten enorme Potentiale bietet. Es demokratisiert den Entwicklungsprozess, indem datenaffine Entwickler und Data Engineers in der Lage sind, KI-gesteuerte Workflows auf deklarative Weise aufzubauen. Gleichzeitig erlaubt es skalierbare, fehlertolerante und effiziente Systeme zu schaffen, die hochgradig integriert in das firmeneigene Datenökosystem funktionieren. Unternehmen, die bereits heute auf Echtzeitdatenprojekte setzen, profitieren von einer solchen Architektur besonders stark.