Künstliche Intelligenz (KI) nimmt in zahlreichen Bereichen unseres Lebens eine immer bedeutendere Rolle ein. Dabei sind gerade Sprachmodelle wie GPT-4, Claude-4 oder andere fortgeschrittene Systeme zu wertvollen Helfern geworden, wenn es darum geht, komplexe Aufgaben zu bewältigen oder als interaktive Schnittstelle zwischen Mensch und Maschine zu fungieren. Ein zentraler Aspekt bei der Interaktion mit solchen Modellen ist das Verständnis ihrer Grenzen und Fähigkeiten. Eine spannende Forschungsfrage lautet: Weiß das Modell, wie oft es ein Tool aufruft? Das Thema klingt auf den ersten Blick vielleicht simpel, doch es steckt eine tiefere Komplexität dahinter. Die Fähigkeit eines Modells, sich korrekt zu erinnern oder zu zählen, wie oft es eine bestimmte externe Ressource – in diesem Fall ein Tool – nutzt, ist eine Herausforderung, die viel über das interne Arbeiten des Modells verrät.
Dabei geht es nicht nur um reines Gedächtnis, sondern auch um die Weise, wie Informationen verarbeitet und gespeichert werden. In einem experimentellen Projekt wurde genau diese Fragestellung untersucht. Dabei wurden Modelle wie Claude-4 in verschiedenen Versionen, GPT-4o und GPT-4.1 sowie weitere Varianten getestet. Jedes Modell sollte ein Tool eine zufällige Anzahl zwischen eins und einhundert Mal aufrufen und anschließend präzise angeben, wie oft es dieses Tool benutzt hat.
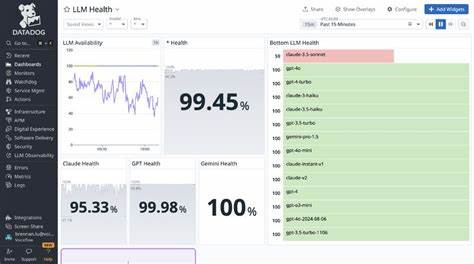
Die Ergebnisse offenbarten interessante Unterschiede in der Fähigkeit der Modelle, die Toolaufrufe korrekt zu zählen und zu berichten. Einige Modelle wie Claude-4-opus und GPT-4.1 zeigten sehr hohe Genauigkeiten von bis zu 100 Prozent bei der korrekten Anzahl, während andere, darunter GPT-4o-mini oder Claude-4-sonnet, deutlich häufiger daneben lagen. Diese Varianz macht sowohl die Fortschritte als auch die aktuellen Grenzen in der Fähigkeit der Modelle sichtbar, interne Handlungen präzise zu verfolgen und auszudrücken. Die Relevanz dieses Experiments geht weit über die reine Zählfähigkeit hinaus.
Es berührt grundlegende Fragen des Modellverständnisses: Haben Sprachmodelle ein echtes inneres Bewusstsein über ihre Interaktionen, oder basieren alle Ausgaben schlicht auf sequenziellen Wahrscheinlichkeiten? Erkennt das Modell, dass es gerade ein Tool benutzt hat, und speichert es diese Information während der Sitzung? Oder entsteht die Antwort rein zufällig aufgrund der Trainingsdaten und Mustererkennung? Darüber hinaus hat die Fähigkeit, Toolaufrufe zu zählen, praktische Implikationen. In vielen Anwendungen ist es notwendig, die Nutzung von Diensten oder Funktionen präzise zu dokumentieren. Beispielsweise bei API-Abrechnungen, Funktionsüberwachung oder der Evaluierung von Modellverhalten in der Forschung. Falsche Angaben oder Inkonsistenzen können große Auswirkungen auf die Zuverlässigkeit und das Vertrauen der Nutzer haben. Aus technischer Sicht hängt die Fähigkeit, Toolaufrufe zu zählen, von mehreren Faktoren ab.
Ein Hauptaspekt ist die Architektur des Modells selbst und wie es kontextuelle Informationen verarbeitet. Manche Modelle integrieren eine Form von Gedächtnis oder verwenden Mechanismen, welche die interne Nachverfolgung von Handlungen erleichtern. Andere sind eher rein autoregressiv, was bedeutet, dass sie auf Basis des vorherigen Outputs und Eingabeaufforderungen reagieren, ohne wirklich „bewusst“ den Überblick zu behalten. Hinzu kommt die Trainingsphase: Je nachdem, wie das Modell trainiert wurde, lernt es Muster und kann wahrscheinliche Antworten auf typische Fragen geben. Wenn Modelle trainiert werden, Muster von Wiederholungen oder Zähler innerhalb des Texts zu erkennen, kann das ihre Fähigkeit verbessern, korrekte Zahlen zu liefern.
Doch wenn die Trainingsdaten hier Lücken aufweisen oder die Zugriffe auf Tools selten geübt wurden, kann das Modell Schwierigkeiten bekommen. Ein weiterer interessanter Punkt ist die dynamische Handhabung von Toolnamen. Das behandelte Experiment zeigte, dass Modelle nicht nur einfache Zählungen durchführen sollten, sondern auch flexibel mit verschiedenen Bezeichnungen umgehen müssen. Dies verlangt eine zusätzliche Komplexität in der Verarbeitung, die nicht immer perfekt gemeistert wird. Die Frage, ob ein Modell weiß, wie oft es ein Tool aufruft, ist also eng mit der Erforschung von Modellbewusstsein, Verlässlichkeit und Interaktionsqualität verknüpft.
Für Anwendungen im Bereich der künstlichen Intelligenz, die hohe Anforderungen an Genauigkeit und Kontrollierbarkeit stellen, ist dieses Wissen entscheidend. Ausblickend öffnen solche Experimente den Weg für eine noch präzisere Kontrolle und Steuerung von KI-Modellen. Indem Entwickler die inneren Funktionen und Grenzen besser verstehen, können sie Modelle optimieren, die transparent und nachvollziehbar agieren. Besonders bei komplexen Multi-Tool-Interaktionen oder in Szenarien mit Abhängigkeiten zwischen verschiedenen Funktionsaufrufen wird das immer wichtiger. Zusammenfassend lässt sich sagen, dass die Fähigkeit eines Modells, die Anzahl seiner Toolaufrufe korrekt zu kennen und anzugeben, derzeit nicht bei allen Systemen gewährleistet ist.
Fortschritte in der Modellarchitektur, Trainingstechniken und Experimentiermethoden tragen jedoch dazu bei, diese Herausforderung zu meistern. Wer sich mit der Entwicklung und Nutzung moderner KI-Modelle beschäftigt, sollte dieses Thema genau verfolgen, da es viel über den Stand der Technik und die zukünftigen Möglichkeiten im Bereich maschinellen Lernens und menschlicher KI-Interaktion verrät.