Große Sprachmodelle (Large Language Models, kurz LLMs) sind heute aus modernen Anwendungen nicht mehr wegzudenken. Sie unterstützen Kundenservice, automatisieren Kommunikationsprozesse und treiben Innovationen in unterschiedlichsten Branchen voran. Dabei vertrauen viele Unternehmen auf Anbieter wie OpenAI, Anthropic oder Google, die leistungsstarke KI-Modelle bereitstellen. Doch ein großes Problem bleibt bestehen: LLM-Anbieter sind nicht immer verfügbar und reagieren gelegentlich mit Verzögerungen oder gar Ausfällen. Die Folge sind nicht nur technische Störungen, sondern im schlimmsten Fall auch das Vertrauensverlust bei Kunden und finanzielle Einbußen.
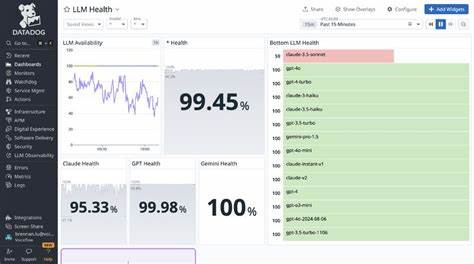
Die spannende Frage lautet deshalb: Muss Ihr Unternehmen diese Ausfälle hinnehmen oder kann es sich dagegen schützen und sogar daraus gestärkt hervorgehen? Die Antwort lautet, dass es möglich ist, trotz Ausfall eines LLM-Anbieters jederzeit zuverlässig zu bleiben, indem man kluge Maßnahmen zur Ausfallsicherung und Fallback-Strategien implementiert. Um diesen Ansatz zu verstehen, lohnt sich ein Blick auf die Herausforderungen mit den aktuellen LLM-Dienstleistern. Während einige Anbieter nominale Verfügbarkeiten von über 99,5 Prozent beanspruchen, bedeuten diese Werte trotz allem mehrere Stunden Ausfallzeit pro Monat – eine kritische Belastung bei Echtzeit-Anwendungen. Zudem lassen sich viele Probleme nicht durch manuelle Eingriffe in Echtzeit beheben, da das Umschalten zwischen Modellen oder Anbietern wertvolle Minuten in Anspruch nehmen kann. Unternehmen, die sich nur auf manuelle Notfallmaßnahmen verlassen, riskieren deshalb erhebliche Serviceunterbrechungen und steigenden Stress bei Technikteams.
Die innovative Lösung heißt automatisierte Fallback-Systeme, die als Puffer fungieren, um nahtlos und ohne wahrnehmbare Unterbrechung auf alternative Modelle oder Anbieter umzustellen. Im Kern geht es darum, das LLM-Backup so zu gestalten, dass es kategorisiert, optimiert und automatisiert abläuft. Ein möglicher Weg ist, Ihre Modelle in klar abgegrenzte Kategorien einzuteilen, die unterschiedliche Anwendungsfälle oder Leistungsprofile abbilden. Zum Beispiel können Modelle gruppiert werden nach "schnell", "intelligent" und "logisch/analytisch". Für jede dieser Kategorien können Sie dann passende Modelle verschiedener Anbieter vorhalten, die sich in Qualität und Antwortzeit ähneln.
Ihre Systemarchitektur entscheidet dann in Echtzeit, welches Modell aus welcher Kategorie gerade genutzt wird und bei Ausfall automatisch zum nächsten in der Reihenfolge wechselt. Dieses Vorgehen stellt sicher, dass Ihre Nutzer stets eine vergleichbare Qualitätserfahrung erhalten, ganz egal, ob Sie gerade auf OpenAI, Anthropic oder einen anderen Anbieter zugreifen. Neben der Modellkategorisierung ist auch eine klare Fallback-Reihenfolge entscheidend. So wird definiert, welcher Anbieter als Erstes, welcher als Zweites oder Drittes im Fall eines Ausfalls einspringt. Ein gut durchdachter globaler Fallback-Order sorgt für maximale Effizienz und geringe Latenz.
Die Implementierung dieser Logik geschieht meist mit sogenannten Agenten, die bei einem Fehler oder Zeitüberschreitung einen transparenten und schnellen Umschaltmechanismus entwickeln. Dies reduziert nicht nur die Ausfallzeit dramatisch, sondern minimiert auch die Komplexität für das Support- und Entwicklerteam. Ein großes Thema bei der Ausfallsicherheit ist auch das Streaming von Antworten, also die schrittweise Übertragung von Textausgaben an Nutzer. Beim Streaming ist es komplizierter, auf einen anderen Anbieter zu wechseln, wenn der erste Token schon gesendet wurde, weil das zu inkonsistenten oder abrupten Nutzererfahrungen führen würde. Daher setzen clevere Systeme darauf, vor dem Start des Streamingvorgangs die Verfügbarkeit zu prüfen, um bei Bedarf sofort umzuschalten und erst gar keine Fehler an den Endkunden weiterzugeben.
Die Vorteile dieser automatisierten Fallback-Lösungen sind vielfältig. Zum einen sinkt die Ausfallzeit auf wenige Millisekunden, wodurch Kunden kaum Störungen und Verzögerungen spüren. Zum anderen werden auch teilweise degradierte Leistungen, etwa wenn öfter kleinere Fehler in den Antworten auftreten, automatisch ausgeglichen, ohne dass manuelles Eingreifen notwendig ist. Somit entstehen weniger Stress für Ihre Technikteams, die ihre Kräfte stattdessen besser in Innovation und Weiterentwicklung investieren können. Dieser Hybrid-Ansatz kombiniert die Zuverlässigkeit automatischer Fallbacks mit der Möglichkeit manueller Optimierungen für Leistung oder Kosten, was die Gesamtarchitektur flexibler und effizienter macht.
Doch solche Ausfallsicherungen bedeuten auch, dass mehr Aufwand bei der Qualitätssicherung betrieben werden muss. Da nicht mehr nur ein einziges Kernmodell evaluiert wird, sondern der gesamte Fallback-Pfad an Modellen, steigen die Test- und Prüfzeiten. Hier zahlt es sich aus, smarte Tools zu nutzen, die automatisierte Vergleiche und Bewertungen ermöglichen – sogenannte LLMs als Juroren –, um die Qualität konsistent über alle Anbieter hinweg zu sichern und gleichzeitig den Evaluationsaufwand beherrschbar zu halten. Die bisherigen Erfahrungen mit automatischen Fallback-Systemen zeigen beeindruckende Erfolge. Unternehmen konnten Uptime-Raten von knapp 99,97 Prozent erzielen, selbst wenn einzelne LLM-Anbieter längere Ausfälle hatten.
Manuelle Eingriffe waren über längere Zeiträume praktisch nicht mehr nötig und die durchschnittliche Umschaltzeit von mehreren Minuten auf Millisekunden reduziert. Damit ist eine neue Stufe der Zuverlässigkeit in KI-gestützten Anwendungen erreicht, die viele Kunden glücklicher und technologische Teams entlastet. Die wichtigste Lehre daraus lautet, dass Anbieterunzuverlässigkeit kein Problem ist, das man einfach hinnimmt, sondern eine technische Herausforderung, die sich mit Kreativität, Systemarchitektur und Automatisierung bewältigen lässt. So können Unternehmen ihren Nutzern einen nahtlosen Service bieten und das Vertrauen in ihre KI-Produkte stärken. Im Zeitalter der künstlichen Intelligenz und vernetzten Systeme wird Robustheit zum Wettbewerbsvorteil.
Wer frühzeitig automatisierte Fallback-Mechanismen integriert, ist auf der sicheren Seite und werden Ausfälle souverän kompensieren. Damit zeigt sich, dass auch in einer Welt scheinbar unzuverlässiger LLM-Anbieter Kundenerlebnisse und Geschäftsprozesse robust und verlässlich bleiben können – und das ganz ohne manuelle Panikreaktionen oder entsprechende Ausfall-Sorgen. Unternehmen sollten deshalb diesen Architekturansatz als unverzichtbaren Teil ihrer KI-Strategie verstehen und weiterentwickeln, um das volle Potenzial von Large Language Models nachhaltig zu nutzen.