In der Welt der Datenverarbeitung und -verwaltung gewinnt Apache Iceberg als modernes Table-Format immer mehr an Bedeutung. Viele Unternehmen setzen auf Iceberg, um große Datenmengen effizient zu verwalten und flexibel abzufragen. Dabei spielt der Katalog eine zentrale Rolle, denn er verwaltet Metadaten wie Tabellenstrukturen, Partitionierungen und Snapshots. Doch bisherige Iceberg-Kataloge sind oft komplex, benötigen aufwendige Setups und sind an bestimmte Cloud-Dienste oder Datenbanken gebunden. Genau an dieser Stelle setzt der Boring Iceberg Catalog an – ein Projekt, das mit nur einer einzigen JSON-Datei auskommt und ohne jegliche Server- oder Cloud-Installation funktioniert.
Dieses Konzept bietet eine äußerst einfache, dennoch wirkungsvolle Lösung, die besonders für Data Engineers, Entwickler und Experimentierfreudige interessant ist, die schnell und unkompliziert mit Iceberg experimentieren möchten. Der Boring Iceberg Catalog wurde von Julien Hurault, einem erfahrenen Data Engineer aus Genf, ins Leben gerufen. Seine Motivation bestand darin, die Komplexität von bestehenden Iceberg-Katalogimplementierungen zu reduzieren und eine leichte, wartungsarme Alternative zu schaffen. Hurault nutzte die Neuerungen von Amazon S3, insbesondere die Möglichkeit von bedingten Schreiboperationen, um Konkurrenzprobleme bei gleichzeitigen Zugriffen auf die Katalogdatei elegant zu lösen. Die Lösung basiert auf einem einzelnen JSON-Dokument, das sämtliche notwendigen Metadaten enthält, und setzt weder eine REST-API noch einen eigenen Server voraus.
Damit repräsentiert der Boring Catalog einen Paradigmenwechsel im Umgang mit Iceberg-Katalogen, indem die Einstiegshürden drastisch gesenkt werden. Die Einfachheit zeigt sich schon beim Setup: Das Einrichten eines neuen Katalogs erfordert lediglich die Installation des Python-Pakets namens "boringcatalog", woraufhin über die Kommandozeile ein Befehl namens "ice init" ausgeführt wird. Dieser Befehl erstellt zwei wichtige Dateien: die eigentliche Katalogdatei namens catalog.json und im Verzeichnis .ice/ eine Indexdatei, die ähnlich wie .
git/index den Pfad zum Katalog speichert. Der Clou hierbei ist, dass der Speicherort der Katalogdatei völlig flexibel gestaltet ist und jeder Pfad unterstützt wird, der kompatibel mit PyArrow oder fsspec ist – von lokalen Dateisystemen bis hin zu S3-Buckets. Somit integriert sich der Catalog nahtlos in unterschiedliche Cloud-Umgebungen oder lokale Setups. Sobald der Katalog eingerichtet ist, kann man Daten auf einfache Weise hinzufügen. Zum Beispiel kann über den Befehl "ice commit" eine Parquet-Datei, die typische Tabellendaten enthält, in den Katalog eingebettet werden.
Dabei wird automatisch eine Standard-Namespace-Struktur angelegt und eine neue Tabelle mit einem beliebigen Namen, etwa "my_table", erzeugt. Die Eingabe ist simpel: Ein Pfad zur Quelldatei wird angegeben und das System übernimmt das Hinzufügen der Daten. Bemerkenswert ist, dass der Boring Catalog derzeit auf Parquet-Dateien als Input beschränkt ist, was jedoch für die meisten Data-Engineering-Anwendungsfälle mehr als ausreichend ist. Das Arbeiten ist dabei dem bekannten Git-Workflow nachempfunden, was sowohl für Entwickler als auch für Dateningenieure intuitiv verständlich ist. Ein bedeutender Aspekt von Iceberg ist das Snapshot-Prinzip, bei dem jede Operation als eigener Snapshot gespeichert wird.
Dies erlaubt eine Versionierung der Tabelleninhalte und macht Datenänderungen jederzeit nachvollziehbar. Die Historie aller durchgeführten Operationen lässt sich bequem über den Befehl "ice log" abrufen. Dieser zeigt ähnlich wie "git log" die letzten Änderungen inklusive Zeitstempel, Art der Operation und Anzahl der betroffenen Dateien oder Zeilen. Diese transparente Historie erleichtert das Debugging, Auditierung und Rückverfolgen von Datenänderungen erheblich. Für Datenexploration und analytische Zwecke ist die Integration von DuckDB als interaktive Shell über den Befehl "ice duck" besonders praktisch.
Diese leichtgewichtige Abfrage-Engine ermöglicht das Durchsuchen der Iceberg-Tabellen im Katalog und erstellt automatisch Views für intuitives Abfragen. Über das DuckDB Web UI erhält man zusätzlich eine visuelle Benutzerschnittstelle, die gerade für Anwender, die Komfort und Übersicht bevorzugen, einen deutlichen Produktivitätsgewinn darstellt. Die Kombination aus einfachem katalogbasiertem Datenmanagement und der Leistungsfähigkeit von DuckDB öffnet neue Möglichkeiten für schnelle, ressourcenschonende Datenzugriffe. Neben der Kommandozeilen-Schnittstelle verfügt der Boring Iceberg Catalog über eine API-basiertes Zugang über Python. Entwickler können das Package direkt in Python-Projekten nutzen, um Tabellen zu laden, Daten hinzuzufügen oder Operationen durchzuführen – ähnlich wie bei PyIceberg, aber mit dem Bonus der unkomplizierten Umgebung.
Beispielhaft lässt sich eine Parquet-Datei in a Python-Datenframe laden, die Tabelle aus dem Katalog referenzieren und mit einem Append-Befehl erweitern. Diese direkte Programmierbarkeit erleichtert die Integration in automatisierte Workflows und Datenpipelines. Darüber hinaus wird auch die Nutzung mit Polars, einer modernen, leistungsstarken Datenframe-Bibliothek, unterstützt. Polars bringt neben Geschwindigkeit auch intuitive Bedienbarkeit mit, sodass Daten direkt aus Parquet-Dateien gelesen und einfach in Iceberg-Tabellen eingeschrieben werden können. Diese Kompatibilität zeigt, dass der Boring Catalog nicht nur experimentellen, sondern auch produktiven Use Cases gerecht wird und mit bestehenden Technologien harmoniert.
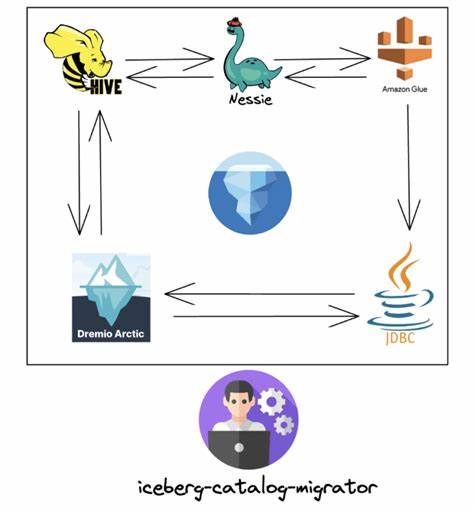
Technisch beruht der Boring Catalog hauptsächlich auf der PyIceberg-Bibliothek, die bereits diverse Katalogimplementierungen mitbringt, darunter Hive, REST, AWS Glue und Nessie. Julien Hurault hat diese Infrastruktur erweitert, um ein einfaches JSON-basiertes Backend zu realisieren. Dies reduziert den Overhead und erhöht die Transparenz, da alle Metadaten direkt in einer einzigen Datei zusammengefasst sind. Das minimiert zugleich Betriebs- und Wartungskosten. Besonders hervorzuheben ist das Handling von gleichzeitigen Schreibzugriffen.
Da keine zentrale Datenbank oder ein Server die Synchronisation übernimmt, greift das System auf die S3-Bedingten Schreiboperationen zurück, vor allem das Conditional Write Feature, das nur dann eine Änderung zulässt, wenn der aktuelle ETag der Datei mit dem erwarteten Wert übereinstimmt. Sollte sich die Datei in der Zwischenzeit verändert haben, schlägt der Schreibvorgang fehl und der Schreibende muss seinen Eingangszustand aktuell nachladen und erneut versuchen. Dieses Verfahren schafft eine einfache, aber effektive Koordination konkurrierender Zugriffe ganz ohne zusätzliche Infrastruktur. Natürlich bringt die Einfachheit auch Einschränkungen mit sich. Der Boring Iceberg Catalog hat momentan keine eingebaute Governance, also keine integrierte Berechtigungs- und Zugriffskontrolle außer den reinen Speicherberechtigungen, die von S3 oder dem zugrunde liegenden Filesystem verwaltet werden.
Für viele professionelle Umgebungen mag dies unzureichend sein, insbesondere wenn komplexe Sicherheitsanforderungen oder unternehmensweite Datenrichtlinien gelten. Dennoch eignet sich die Lösung perfekt als Spielwiese, zum Experimentieren und für kleine bis mittelgroße Projekte. Der Blick in die Zukunft zeigt spannende Entwicklungsmöglichkeiten. So sind bereits Ideen vorhanden, eine REST-API-Schnittstelle auf Basis des Boring Catalog zu realisieren, um die Interoperabilität mit anderen Tools und Plattformen weiter zu verbessern. Dies würde es beispielsweise ermöglichen, Snowflake oder andere Datenplattformen direkt mit dem einfachen JSON-Katalog kommunizieren zu lassen und so die Brücke zwischen experimentellen und produktiven Umgebungen zu schlagen.
Zudem plant Julien Hurault, das CLI-Tool um Funktionen wie Partitionierungsspezifikationen, spezifische Merge-Operationen oder umfassendere Unterstützung für Schema-Evolution zu erweitern. Damit könnte der Boring Catalog an Flexibilität und Funktionalität gewinnen, ohne seine grundlegende Philosophie der Einfachheit zu verlieren. Insgesamt zeigt der Boring Iceberg Catalog, dass man mit minimalem Aufwand und geringem Setup viel erreichen kann. Durch die Fokussierung auf eine einzige JSON-Datei reduziert sich die Komplexität drastisch, sodass das Potenzial von Iceberg auch für jene zugänglich wird, die keine aufwändige Infrastruktur aufbauen möchten. Die Git-ähnliche Bedienung trifft den Nerv moderner Entwickler und sorgt für eine vertraute und effiziente Nutzererfahrung.
Wer sich mit Iceberg beschäftigt, sollte den Boring Catalog als eine spannende Alternative oder Ergänzung im Hinterkopf behalten. Für Experimentierzwecke, schnelle Prototypen, oder einfach zum Verstehen der Grundlagen von Iceberg-Operationen ist er ein wertvolles Werkzeug. Gleichzeitig bietet er eine solide Grundlage, um weiterführende, individuell angepasste Kataloglösungen zu entwickeln oder schlichtweg die Komplexität von Datenkatalogen zu hinterfragen. Der Trend zu leichteren, nutzerfreundlichen Tools im Datenmanagement wird durch den Boring Iceberg Catalog eindrucksvoll bestätigt und könnte den Weg weisen für weitere Innovationen, die bisherige Standards aufbrechen und neue Wege des Arbeitens mit großen Daten schaffen. Wer an der Spitze der Data Engineering Bewegung bleiben möchte, sollte diese Entwicklung aufmerksam verfolgen und ausprobieren.
Fazit: Der Boring Iceberg Catalog beweist, dass weniger oft mehr ist – mit nur einer JSON-Datei und ohne komplexes Setup können Data Engineers effiziente, transparente und leicht zugängliche Iceberg-Kataloge betreiben. Diese Einfachheit in Kombination mit moderner Technik wie S3 conditional writes macht den Catalog zu einem idealen Werkzeug für schnelle Fortschritte im Datenökosystem und einer erfrischenden Alternative zu etablierten Lösungen.