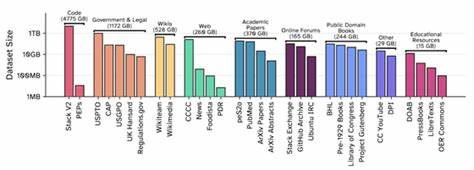
In der Welt der künstlichen Intelligenz (KI) und insbesondere bei der Entwicklung von großen Sprachmodellen (Large Language Models, LLMs) spielen hochwertige Datensätze eine entscheidende Rolle. Ohne umfangreiche und vielfältige Trainingsdaten können Sprachmodelle kaum die Fähigkeit erlangen, Sprache natürlich zu verstehen und zu generieren. Im Juni 2025 präsentierte EleutherAI mit dem Common Pile v0.1 einen der wegweisendsten Fortschritte im Bereich offener und öffentlich zugänglicher Trainingsdaten. Als Nachfolger des bereits bahnbrechenden Pile-Datensatzes aus dem Jahr 2020 vereint der Common Pile beeindruckende 8 Terabyte an Texten aus öffentlich zugänglichen und offen lizenzierten Quellen.
Dieses Projekt ist mehr als nur eine Datenansammlung – es ist ein Meilenstein hin zu mehr Transparenz, Qualität und Gemeinschaft in der KI-Forschung. EleutherAI, eine Community, die für ihre Open Source- und Open Science-Philosophie bekannt ist, startete vor über vier Jahren mit dem ursprünglichen Pile-Datensatz, der damals 800 Gigabyte umfasste. Schon damals zeichnete sich die Sammlung durch die Integration unterschiedlicher Datenquellen aus, darunter wissenschaftliche Veröffentlichungen, Forenbeiträge und Programmiercode. Diese Vielfalt ermöglichte es, Sprachmodelle zu trainieren, die nicht nur natürliche Sprache, sondern auch technischen und spezialisierten Jargon verarbeiten können. Mit dem Common Pile v0.
1 wurde dieses Konzept auf eine neue Ebene gehoben: Um fast das Zehnfache vergrößert und noch rigoroser hinsichtlich Lizenzbedingungen geprüft, schafft der Common Pile eine vertrauenswürdige Basis für moderne KI-Trainings. Einer der zentralen Werte bei EleutherAI ist die Offenheit. Die Offenheit bezieht sich nicht nur auf die Tatsache, dass der Datensatz öffentlich zugänglich ist, sondern auch darauf, dass alle enthaltenen Texte unter sogenannten offenen Lizenzen stehen oder sich im Public Domain befinden. Diese Lizenzen gestatten die freie Nutzung, Modifikation und Weiterverbreitung der Inhalte ohne rechtliche Einschränkungen oder das Risiko von Urheberrechtsverletzungen. Um das sicherzustellen, arbeitete EleutherAI eng mit Rechtsexperten zusammen und entwickelte klare Kriterien für zulässige Lizenztypen.
Dabei wurde auf bewährte Standards aus der Open-Source-Community wie die Open Knowledge Foundation und den Blue Oak Council zurückgegriffen. Die Herausforderung, offene Lizenzen sicher zu identifizieren, ist keineswegs trivial. Im Gegensatz zu Software, bei der sich Lizenzinformationen meist klar dokumentieren lassen, sind Texte oft lizenziert oder als Public Domain deklariert, ohne dass diese Angaben leicht maschinell extrahiert werden können. Besonders die Unterscheidung zwischen sogenannter legaler Public Domain, die von Jurisdiktion zu Jurisdiktion unterschiedlich ausgelegt wird, und tatsächlich frei zur Nutzung stehenden Werken erfordert sorgfältige manuelle Prüfung und vertrauenswürdige Metadatenquellen. EleutherAI konnte auf Partnerschaften mit Institutionen wie der Library of Congress und dem Internet Archive zurückgreifen, die bereits über enorme Mengen an Public Domain-Werken verfügen, damit diese in den Common Pile Einzug halten.
Eine weitere Besonderheit dieses Datensatzes ist die Integration von speziell kuratierten Komponenten, die sowohl natürliche Sprache als auch Code umfassen. Die Berücksichtigung von Code im Training von Sprachmodellen hat sich in den letzten Jahren als äußerst wertvoll erwiesen, da sie die Fähigkeit der Modelle verbessert, technische Anfragen besser zu verstehen, Programmierhilfe zu leisten und Syntax korrekt zu verarbeiten. Für den Common Pile wurde beispielsweise die Stack v2 Codebasis in abgesicherter, offen lizenzierter Version aufgenommen. Dies macht den Common Pile für Entwickler von KI-Systemen, die sich auf Programmierunterstützung oder technische Dokumentation spezialisieren, besonders attraktiv. Neben der Sammlung selbst veröffentlichte EleutherAI mit dem Common Pile auch erste darauf trainierte Sprachmodelle namens Comma v0.
1. Diese Modelle mit sieben Milliarden Parametern wurden auf Einkristallmengen von 1 Billion und 2 Billionen Tokens trainiert und zeigen in Leistungstests, dass sie Modelle mit unlizenzierter Datenbasis in nichts nachstehen. Diese Erkenntnisse widerlegen die oft geäußerte Annahme, dass nur nicht offen lizenzierte Daten zu besseren KI-Modellen führen könnten. Stattdessen zeigt sich, dass sorgfältig kuratierte offene Daten durchaus mit den Ergebnissen konkurrieren können, die sonst nur mit proprietären, nicht einsehbaren Datensätzen erzielt werden. Die Bedeutung dieser Transparenz kann gar nicht hoch genug eingeschätzt werden.
In den letzten Jahren haben juristische Auseinandersetzungen um den Einsatz von Trainingsdaten in KI-Systemen zugenommen. Viele große Technologieunternehmen reagieren darauf mit einer zunehmenden Geheimhaltung bezüglich ihrer Datenquellen. Dies erschwert Forschern und der Öffentlichkeit gleichermaßen den Einblick in die Zusammensetzung der Trainingsdaten, was wiederum Vertrauen und die Möglichkeit unabhängiger Forschung erschwert. Durch die Veröffentlichung eines vollständig offene und transparenten Datensatzes sowie der dazugehörigen Modelle setzt EleutherAI ein starkes Zeichen für mehr Offenheit und Nachvollziehbarkeit. Auch auf der Seite der Technikentwicklung trägt die Freiheit über offen zugängliche Daten maßgeblich zu schnelleren Fortschritten bei.
So ermöglichen identische Datengrundlagen für Trainings und Tests von KI-Modellen bessere Vergleichsstudien. Neue Ansätze zur Architektur oder Algorithmusoptimierung lassen sich unter gleichen Bedingungen überprüfen, was den Innovationsprozess beschleunigt und die Reproduzierbarkeit von Studien gewährleistet. Projekte wie RWKV oder Mamba nutzen den Common Pile als Referenzbenchmark und profitieren dadurch direkt von der öffentlichen Verfügbarkeit und dem hohen Qualitätsstandard des Datensatzes. Neben den technischen und rechtlichen Herausforderungen ist der Common Pile auch ein Symbol für die wachsende Zusammenarbeit zwischen der Open Source AI Community und kulturellen Institutionen. Bibliotheken, Archive und Museen besitzen riesige Mengen an Werken, die idealerweise für die KI-Entwicklung nutzbar gemacht werden könnten.
Allerdings sind viele dieser Werke bisher nur in schlechter digitalisierter Form oder mit unzureichenden Metadaten verfügbar. Moderne Open Source Technologien wie Docling für optische Zeichenerkennung (OCR) und Whisper für Audio-Transkription eröffnen hier neue Möglichkeiten, diese Daten aufzubereiten und zugänglich zu machen. EleutherAI strebt daher langfristig Partnerschaften mit eben diesen Institutionen an, um eine Brücke zwischen kulturellem Erbe und modernster KI-Technologie zu schlagen. Der Common Pile v0.1 steht für eine neue Ära der offenen KI-Forschung, in der Wissen, Ressourcen und Daten verantwortungsvoll geteilt werden, um faire und leistungsfähige Systeme zu schaffen.
Die Veröffentlichung auf Plattformen wie GitHub, Hugging Face und arXiv stellt sicher, dass Forscher weltweit unkomplizierten Zugriff haben und von den besten Werkzeugen, Methoden und Datensätzen profitieren können. Auch die Entwicklung und Bereitstellung von Werkzeugen zur Datenverarbeitung und Lizenzanalyse wird weiter vorangetrieben, um zukünftige Datensammlungen noch besser und effizienter realisieren zu können. Ein zentrales Ziel von EleutherAI ist es, die Barrieren für den Zugang zu hochwertiger KI-Technologie zu senken und die Beteiligung an der KI-Entwicklung global zu verbreitern. Gerade in Zeiten, in denen immer mehr Unternehmen mit proprietären Daten und abgeschotteten KI-Modellen agieren, bietet die Öffnung von Ressourcen wie dem Common Pile eine demokratisierende Kraft. Dies fördert nicht nur die wissenschaftliche Forschung und industrielle Innovation, sondern stärkt auch die ethische Verantwortung und das Vertrauen der Gesellschaft in KI-Anwendungen.
Blickt man in die Zukunft, so ist der Common Pile v0.1 nur der Anfang einer langfristigen Strategie, die regelmäßig aktualisierte und verbesserte offene Datensätze bereitstellen möchte. Das kontinuierliche Sammeln, Kuratieren und Veröffentlichen von offen lizenzierten Inhalten ist eine Herausforderung, aber auch eine Chance für die gesamte KI-Community. Mit zunehmender Menge und Qualität wird es möglich sein, immer leistungsfähigere Modelle zu entwickeln, die zudem die Grundsätze von Transparenz, Zugänglichkeit und Fairness wahren. In diesem Zusammenhang könnte auch die Nutzung von offen lizenzierten Nachtrainingsdaten verstärkt in den Fokus rücken, um den Comma-Modellen noch breiter einsetzbare Fähigkeiten zu verleihen.