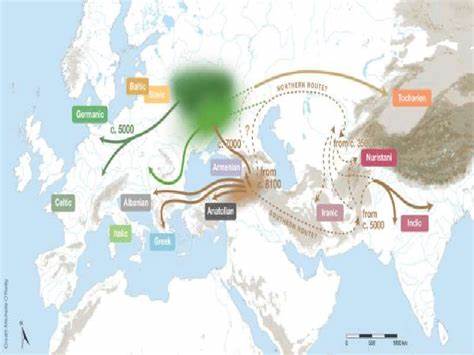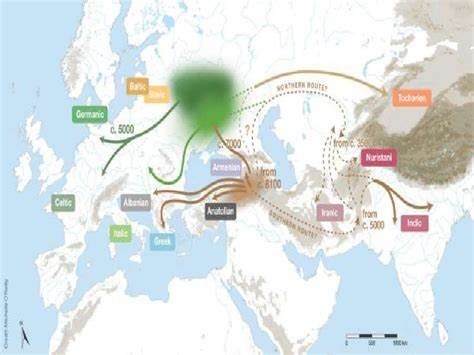
Die Frage nach dem Ursprung der indogermanischen (auch indoeuropäischen) Sprachfamilie gehört zu den bedeutendsten und am intensivsten diskutierten Themen innerhalb der historischen Linguistik. Verschiedene Modelle versuchen zu erklären, wo und wie diese weit verzweigte Sprachfamilie entstanden ist. Besonders im Fokus stehen dabei die Theorie eines ursprunglichen anatolischen Siedlungsgebiets sowie das Modell der eurasischen Steppengebiete, das vielfach mit dem sogenannten Steppenstammmodell verknüpft ist. In den letzten Jahren rückten sogenannte sprachphylogenetische Methoden und computergestützte Analysen verstärkt in das Zentrum der Forschung. Diese setzen formale Modelle ein, um anhand von Wortlisten und lexikalischen Daten Sprachbäume zu rekonstruieren, die genealogische Verwandtschaften abbilden.
Ein neuerer Ansatz ist die Berücksichtigung sogenannter „sampled ancestors“, also von rekonstruierten oder tatsächlichen Vorfahrensprachen innerhalb der phylogenetischen Bäume. Eine aktuelle Studie von Heggarty et al. (2023) verspricht auf Basis eines umfangreichen digitalen Datensatzes eine neue Perspektive, welche eine Art „hybrides“ Modell des indogermanischen Ursprungs unterstützen soll. Doch wie belastbar sind diese Ergebnisse wirklich? Die kritische Aufarbeitung dieser Methode und ihrer Resultate zeigt komplexe Zusammenhänge, die weiterführende Überlegungen erfordern.Zunächst ist festzuhalten, dass der neu entwickelte Datensatz IE-CoR (Indo-European Cognate Reflexes) deutliche Fortschritte im Vergleich zu früheren lexikografischen Sammlungen aufweist.
Über 80 Experten aus unterschiedlichsten IE-Sprachgruppen haben über vier Jahre daran gearbeitet, sprachhistorisch äußerst sorgfältige Wortlisten zu erstellen, welche 170 Konzepte in 161 Sprachvarianten abdecken – darunter auch 52 historische Formen. Diese sorgfältige Kuratierung deutet auf eine verbesserte Datenqualität hin, welche die Basis für eine fundierte phylogenetische Analyse bildet. Dennoch zeigen sich erhebliche Probleme bei der Behandlung von Konvergenzen, Lehnwörtern und sogenannten „derivational drift“-Phänomenen, bei denen unabhängige Wortbildungen aus demselben Ursprungsstamm entstehen, die nicht unbedingt eine echte Verwandtschaft indizieren. Gerade das präzise Markieren von echten Kognaten im Gegensatz zu ringförmigen Entlehnungen oder Arealgriffen bleibt eine Herausforderung und beeinträchtigt damit die Aussagekraft der rekonstruierten Sprachbäume.Die methodische Herangehensweise von Heggarty et al.
basiert auf typischer Bayesianischer Phylogenetik, umgesetzt mit der Software BEAST. Die Analyse wertet lexikalische Daten in probabilistischen Modellen aus, um Verzweigungen und Abstammungsverhältnisse sowie Zeitpunkte von Aufspaltungen (Divergenzzeiten) zu schätzen. Die Resultate zeichnen ein Bild, das einerseits die traditionelle Anatolien-Hypothese stützt – mit einer ersten Abtrennung des anatolischen Zweigs zwischen 4740 und 7610 vor Christus –, andererseits aber für spätere Verzweigungen Steppe als Ursprungsregion vorschlägt. Das Muttermal einer „hybriden“ Herkunft ergibt sich laut den Autoren daraus, dass unterschiedliche Zweige der Sprachfamilie jeweils unterschiedliche geografische Heimatregionen nachweisen sollen, wobei migrations- und kontakthistorische Prozesse ein komplexes Geflecht weben.Doch bei genauerer Betrachtung des entstandenen „Maximum Clade Credibility“-Baums offenbaren sich gravierende Mängel und Zweifel an der Plausibilität.
Viele innerfamiliäre Verästelungen besitzen eine niedrige statistische Unterstützung und widersprechen etablierten historischen und linguistischen Erkenntnissen. So wird etwa eine Nähe zwischen Hethitisch und Tocharisch postuliert, die kaum linguistisch stichhaltig belegt ist, ebenso wie die unumstrittene Stellung einiger Sprachen in der traditionellen Klassifikation infrage gestellt wird. Besonders bemerkenswert ist eine Art „Ur-Rake“ am Stammbaum, bei dem sich wichtige Hauptzweige als Multifurkation darstellen, was angesichts von bekannten Entwicklungssequenzen als wenig sinnvoll erscheint.Eine mögliche Erklärung der unsicheren Baumtopologie liegt im Verhältnis von Datensätzen und Sprachen. Mit 170 Konzepten auf 161 Sprachvarianten ist die Datenmenge zwar groß, aber im statistischen Sinne nicht ausreichend, um eine robuste Knotenauflösung zu gewährleisten.
Die Komplexität und Variation der Sprachdaten verlangen mehr Vergleichsinseln, um zufällige oder konvergente Gemeinsamkeiten sinnvoll zu differenzieren. Die Alternative, weniger Sprachvarianten zu analysieren und dafür stärkere Fokussetzung auf rekonstruktive Vorfahren oder Cluster bietet die sogenannte „reduktionistische“ Perspektive, die etwa von der Moskauer Schule favorisiert wird. Dabei werden Zwischenstufen imaginärer Sprecher oder proto sprachliche Aggregationen in die Modellierung einbezogen, um das Rauschen übermäßiger Diversity zu minimieren.Dazu kommt, dass trotz der hohen Qualität des IE-CoR-Datensatzes weiterhin problematische Faktoren bestehen. Beispielsweise wird die Markierung von Lehnwörtern und Pflege von kontextuellen Bedeutungen teils zu mechanisch gehandhabt.
Fälle von Bedeutungswandel infolge interner Sprachentwicklung werden teilweise fälschlich als Lehnübernahmen gewertet oder umgekehrt. Ein besonders anschauliches Beispiel liefert der Umgang mit dialektalen Sonderfällen wie dem Tsakonischen Griechisch oder Kashmiri, wo erhebliche unerkannte Lehnwörter den phylogenetischen Platz verzerren können. Bei Kashmiri führt dies etwa dazu, dass die Sprache unnötig tief in den indoarischen Zweig hineingesetzt wird, was objektiv nicht schlüssig ist.Ein weiterer Kritikpunkt betrifft die semiotische Argumentation der Autoren in Hinblick auf Sprachpaleontologie. Heggarty et al.
vertreten eine radikale Ansicht, dass lexikalische Übereinstimmungen auf Proto-Ebene nicht zwingend dieselben Bedeutungen tragen müssen wie in den Tochtersprachen und folgern daraus relativierende Einschätzungen zum Wissenstand der ursprünglichen Sprecher. Dieses Vorgehen widerspricht gängigen Prinzipien der semantischen Rekonstruktion und wird von vielen Sprachhistorikern als spekulativ und wenig überzeugend bewertet. Gerade bei zentralen Konzepten wie ‘Rad’ oder ‘Pferd’ liefern traditionelle Analysen weitaus stabilere Hypothesen für den kulturellen Kontext der frühen Indogermanen.Unterm Strich zeigt sich, dass die aktuelle Studie zwar wichtige Fortschritte bei der Datenbasis markiert, insbesondere durch die Einbindung von Fachlinguisten und strengere Qualitätskontrollen. Doch die daraus resultierenden phylogenetischen Modelle sind in ihrer Aussagekraft begrenzt und können aus heutiger Sicht nicht als abschließende Evidenz für ein hybrides Ursprungsmodell des Indogermanischen gelten.
Dies liegt nicht zuletzt an methodischen Grenzen, datenbedingten Herausforderungen, dem Spannungsfeld zwischen semantischer Komplexität und statistischer Modellierung sowie divergenten fachwissenschaftlichen Traditionen.Für den weiteren Fortschritt erscheint es daher sinnvoll, eine ausgewogene Herangehensweise anzustreben, bei der computergestützte Modelle nicht die klassische eindimensionale Stammbaumlogik ersetzen, sondern sie ergänzen und mit etablierten linguistischen sowie archäologischen Erkenntnissen verknüpfen. Innovative Ansätze wie die Einbindung von Zwischenstufensprachen, präzisere Distinktionen zwischen Erbworten und Lehnwörtern oder der stärkere Fokus auf semantische Entwicklungen können die Qualität der Analysen erhöhen. Gleichzeitig bedarf es verstärkter Transparenz in der methodischen Offenlegung und einer kritischen Diskussion im wissenschaftlichen Austausch.Abschließend bleibt festzuhalten, dass der Begriff „hybrides Modell“ im indogermanischen Kontext mit Vorsicht zu verwenden ist.
Das klassische Verständnis hybrider Sprachen betrifft Sprachmischungen oder Mehrfachabstammungen einzelner Varietäten, was hier nicht gemeint ist. Vielmehr plädieren die Autoren für einen Kompromiss zwischen älteren Modellen zu Anatolien- und Steppenherkunft, was zwar moderat als „hybrid“ bezeichnet wird, aber letztendlich eher eine Nebeneinanderstellung oder sukzessive Migration annimmt statt eine echte genetische Mischung. Die Kritik betont, dass eine solche Terminologie eher verwirrend und missverständlich sein kann und einer klaren Differenzierung bedarf.Insgesamt zeigt die Debatte rund um die jüngsten Sprachbäume mit „sampled ancestors“, dass die Erforschung der indogermanischen Ursprünge weiterhin ein komplexes Feld bleibt. Fortschritte in Datensammlung, Algorithmen und interdisziplinären Zugängen versprechen neue Erkenntnisse, zugleich setzt die Gewinnung belastbarer Ergebnisse einen hohen Anspruch an Datenqualität, methodische Präzision und fachlichen Abgleich voraus.
Die jüngsten Analysen von Heggarty et al. tragen spürbar zur Dynamik dieser Diskussion bei, ohne jedoch eine definitive Lösung anzubieten. Damit bleiben klassische und neue Forschungsparadigmen im produktiven Spannungsfeld und treiben die Erforschung der indogermanischen Sprachfamilie auch zukünftig voran.