Die Herkunft und Entstehung der indogermanischen (Indo-Europäischen) Sprachfamilie gehört zu den faszinierendsten und zugleich umstrittensten Themen der historischen Sprachwissenschaft und Archäologie. In den letzten Jahrzehnten hat die computergestützte Analyse von Sprachdaten neue Impulse geliefert, um diese Entstehungsgeschichte besser zu verstehen. Ein besonderer Fokus liegt dabei auf sogenannten Sprachbäumen mit „sampled ancestors“, einer Methode der phylogenetischen Rekonstruktion, die helfen soll, Verwandtschaftsbeziehungen und zeitliche Abfolgen von Sprachen zu bestimmen. Eine neu erschienene Studie von Heggarty et al. (2023) behauptet, mit dieser Methode Hinweise für ein hybrides Modell des Indo-Europäischen Ursprungs gefunden zu haben, das sowohl auf die anatolische Hypothese als auch die Steppe-Hypothese Bezug nimmt.
Doch unterstützt die Datengrundlage und Methodik diese Schlussfolgerung tatsächlich? Diese Frage beschäftigt zahlreiche Forscher und bietet Anlass für eine intensive Diskussion. Das Modell der Sprachbäume mit sampled ancestors beruht auf der Idee, dass innerhalb eines phylogenetischen Baums nicht nur „abgelebte“ Vorfahren rekonstruiert werden, sondern auch einzelne Sprachstufen und Zwischenformen, die als direkte Vorfahren lebender oder bekannter historischer Sprachen angenommen werden können. Diese Methode verspricht eine feinere zeitliche und strukturelle Auflösung als herkömmliche Bäume, die ausschließlich heutige Sprachen oder rekonstruierte Protolangstufen als Blätter führen. Heggarty und Kollegen haben dafür eine umfangreiche Datenbank namens IE-CoR (Indo-European Cognate Reflexes) entwickelt, in der 161 Sprachen und Sprachstufen anhand von 170 Konzepten lexikalisch erfasst und verglichen werden. Die IE-CoR-Datenbank stellt zweifellos einen Fortschritt im Vergleich zu früheren Arbeiten von Gray und Atkinson (2003) sowie Bouckaert et al.
(2012) dar. Sie zeichnet sich durch eine sorgfältige lexikalische Kuration aus, die von einem großen internationalen Team von Experten für verschiedene indo-europäische Zweige entwickelt wurde. Dabei gilt besonders die Differenzierung von echten Verwandtschaftsbeziehungen (Kognaten) und Kontakten beziehungsweise Lehnwörtern als wichtige Grundlage für ein präziseres phylogenetisches Modell. Dennoch zeigen kritische Analysen von Kassian und Starostin (2025), dass trotz des verbesserten Datenmaterials einige fundamentale Probleme bestehen, die die Robustheit und Validität der erzielten Baumstrukturen und Zeitdaten beeinträchtigen könnten. Eines der größten Probleme liegt in der Unterscheidung von echtem Verwandtschaftserbe und arealer Diffusion.
Wenn Sprachen über lange Zeiträume und engem geografischem Kontakt einander beeinflussen, entstehen Gemeinsamkeiten, die nicht auf genetische Verwandtschaft zurückzuführen sind. Dies kann gerade bei den komplexen Kontaktsituationen in Europa und Westasien zu falschen Verbindungen im phylogenetischen Baum führen. Darüber hinaus wird der Einfluss von Derivationsdrift – also die unabhängige Entstehung von morphologisch ähnlichen Wörtern aus derselben Wurzel in verschiedenen Sprachzweigen – oft nicht ausreichend berücksichtigt. Hierdurch können wiederum vermeintliche Verwandtschaften suggeriert werden, die tatsächlich keine sind. Die chronologische Kalibrierung der Sprachbäume, also die zeitliche Einordnung der Aufspaltung der Sprachzweige, wurde anhand von 52 historischen Sprachen vorgenommen.
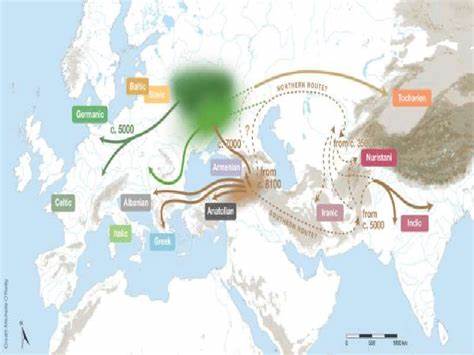
Die daraus resultierenden Datierungen für die erste Aufspaltung innerhalb des Indo-Europäischen werden zwischen etwa 4740 und 7610 vor Christus angesetzt, mit einem Median um 6120 vor Christus. Diese Datierung steht in Verbindung zur oft diskutierten Anatolischen Hypothese, welche die Ursprünge der indogermanischen Sprachen mit der Verbreitung der neolithischen Landwirtschaft aus Anatolien nach Europa verbunden sieht. Demgegenüber liegt die Steppe-Hypothese, die die Entstehung in der eurasischen Steppe des 4. Jahrtausends v. Chr.
postuliert, zeitlich später. Die von Heggarty et al. vorgeschlagene „hybride“ Interpretationslinie versucht, beide Theorien zu einem gemeinsamen Narrativ zu verbinden, indem frühe Abspaltungen auf das anatolische Gebiet datiert werden, während spätere Ausbreitungen einige der Sprachzweige mit der Steppe in Verbindung bringen. Kritiker bemängeln allerdings, dass diese Kombination nicht vollständig stichhaltig ist. So weisen Kassian und Starostin darauf hin, dass mehrere wichtige Verzweigungen im Baum eine sehr geringe statistische Unterstützung aufweisen, die Gesamtstruktur des Baums nicht schlüssig ist und dass damit verbundene historische Hypothesen in mehreren Punkten der klassischen Sprachforschung widersprechen.
Besondere Skepsis besteht zudem gegenüber der ausgegebenen topologischen Struktur. Zum Beispiel wird eine unerwartete und zweifelhafte Einheit von Hethitisch und Tocharisch vorgeschlagen, für die bislang keine solide linguistische Basis existiert. Außerdem zeigt der Baum eine multifurcate Grundstruktur, die kaum bestimmte Abspaltungen klar abbildet, sondern eher ein unscharfes Bild bietet. Dies könnte darauf hindeuten, dass angesichts der hohen Diversität (161 Sprachstufen, darunter viele ausgestorbene Sprachen) und der vergleichsweise geringen Anzahl lexikalischer Merkmale (170 Konzepte) die Datenbasis für ein belastbares Ergebnis nicht ausreichend ist. Die Kombination eines großen Taxa-Sets mit einer begrenzten Zahl von Vergleichsmerkmalen erhöht die Wahrscheinlichkeit für statistische Artefakte.
Ein weiterer Kritikpunkt betrifft die Behandlung von Lehnwörtern und internen semantischen Entwicklungen. In einigen Fällen wurden entlehnte Wörter nicht als solche erkannt, was besonders bei Sprachen wie Tsakonisch-Griechisch oder Kashmiri zu falschen Positionierungen im Baum führt. So ist es beispielsweise beim Kashmiri vorgekommen, dass zahlreiche indoiranische Lehnwörter nicht korrekt als solche markiert wurden und somit die Einordnung des Kashmiri mitten in der indoiranischen Gruppe beeinflussen. Dies zeigt die Schwierigkeiten, die mit der Erkennung und Kategorisierung von Lehnwörtern in komplexen Sprachsituationen verbunden sind. Auch die sprachhistorische „Sprachpaläontologie“, also die Erneuerung von Konzepten durch Rekonstruktion urtümlicher Wortschätze, wird in der neuen Studie kritisch betrachtet.
Heggarty et al. hinterfragen etablierte Vorstellungen, etwa ob Proto-Indo-Europäisch tatsächlich bestimmte Begriffe wie „Rad“ oder „Pferd“ so verwendet haben könnte, wie klassische Linguisten dies annehmen, und schlagen alternative, teilweise abstraktere Bedeutungen vor. Dies führte zu hitzigen Debatten, weil solche Interpretationen bislang gut belegte methodische Prinzipien der historischen Sprachforschung in Frage stellen. Trotz der zahlreichen Kritikpunkte stellt die Studie von Heggarty et al. einen wichtigen Schritt dar, vor allem durch die Zusammenarbeit mit erfahrenen Indo-Europäisten und die Erstellung einer großen, sorgfältig kuratierten Datenbasis.
Gleichwohl sind die Ergebnisse keinesfalls eindeutig und sollten nicht als endgültiger Beweis für ein hybrides Ursprungsmodell interpretiert werden. Vielmehr verdeutlichen sie die Herausforderungen, vor denen Computermodelle bei der Rekonstruktion komplexer prähistorischer Sprachveränderungen stehen. Alternativ schlagen Kassian, Starostin und andere Forscher vor, dass die Verwendung von Zwischenstufen und rekonstruierten ancestral states, anstatt einer Vielzahl moderner oder mittelalterlicher Sprachen als Taxa, eine robustere Klassifikation ermöglichen könnte. Dies würde dem Modell eine Solidität verleihen und gleichzeitig den Einfluss von Arealenffekten und Lehnwörtern verringern. Außerdem zeigen Studien, dass eine geringere Anzahl sorgfältig ausgewählter Sprachen und eine größere Menge an lexikalischen Merkmalen bessere Ergebnisse bringen als umgekehrt.
Insgesamt zeigt die Debatte um die Sprachbäume mit sampled ancestors, dass die Forschung zur Herkunft der indogermanischen Sprachen weiterhin lebendig und vielschichtig ist. Die Kombination von Computermethoden, umfassender lexikaler Datensammlung und klassischer Sprachvergleichung birgt großes Potenzial, bedarf aber einer vorsichtigen Anwendung und interdisziplinärer Absicherung. Ein hybrides Modell des Indo-Europäischen Ursprungs, das Teile der anatolischen und der steppebasierten Hypothese verbindet, ist weiterhin umstritten und keineswegs abschließend bewiesen. Die komplexen sprachhistorischen, archäologischen und genetischen Daten müssen weiterhin kritisch betrachtet und ausgewertet werden, um dem Ziel einer soliden Theorie von Herkunft und Ausbreitung der indogermanischen Sprachen näherzukommen.