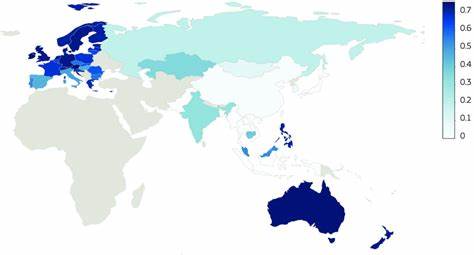
Sprache ist weit mehr als nur ein Kommunikationsmittel. Sie verbindet Menschen, prägt Identitäten und beeinflusst gesellschaftliche sowie wirtschaftliche Interaktionen auf vielfältige Weise. Die Analyse sprachlicher Verbindungen zwischen Ländern und innerhalb von Staaten bietet daher wichtige Einblicke in kulturelle Affinitäten, Handelsbeziehungen und Migrationstrends. In diesem Kontext gewinnt ein neu entwickeltes Datenset, das die linguistische Vernetzung weltweit abbildet, besondere Bedeutung. Dieses Dataset liefert nicht nur einen Überblick über die Verbreitung von 6.
675 Sprachen in 242 Ländern und Territorien, sondern differenziert auch verschiedene Dimensionen sprachlicher Nähe und Gemeinsamkeiten auf eine bislang unerreichte Weise. Es ermöglicht Einblicke sowohl in offizielle Sprachstatus als auch in die tatsächliche Verbreitung und somit in die kommunikative Wirklichkeit von Bevölkerungen. Die Grundlage des Datensatzes bildet die umfassende Sammlung von Ethnologue: Languages of the World, einem weltweit anerkannten Nachschlagewerk für Sprachstatistiken. Darauf aufbauend wurden elf verschiedene Indizes entwickelt, die diverse Aspekte der Sprachvernetzung detailgenau erfassen. Diese Indizes differenzieren beispielsweise zwischen Sprachen, die als Amtssprachen fungieren, Muttersprachen der Bevölkerung und erlernten Zweitsprachen.
Darüber hinaus werden sogenannte proximale Sprachbeziehungen berücksichtigt, welche die evolutionäre Nähe zwischen verwandten Sprachen messen und so Kommunikationsmöglichkeiten auch jenseits identischer Sprachen erfassen. Die Betrachtung von offiziellen Sprachen erfolgte in zwei Varianten: Eine liberalere, welche alle Sprachen berücksichtigt, die irgendeine offizielle Funktion einnehmen, etwa auf nationaler oder regionaler Ebene, und eine restriktivere, die sich auf national anerkannte Amtssprachen beschränkt. Diese Differenzierung ist wichtig, da Amtssprachen häufig eine zentrale Rolle in Verwaltung, Bildung und Rechtssystem spielen und damit besonders starken Einfluss auf inter- und intranationale Verständigung besitzen. Die Analyse solcher offiziellen Sprachverbindungen zeigt, wie viele Länder etwa durch koloniale Vergangenheiten oder gemeinsame Verwaltungssprachen direkt miteinander verbunden sind. Neben den offiziellen Sprachen liegt ein Fokus auf den „Common Native Language“-Indizes (CNL).
Diese messen die Verbreitung von Muttersprachen in Ländern und die Überschneidungen zwischen diesen Populationen. So lassen sich kulturelle Verwandtschaften und ethno-linguistische Bindungen erkennen, die sich oftmals in starken sozialen und politischen Beziehungen manifestieren. Der Index umfasst eine Vielzahl von Sprachen, was ihn besonders aussagekräftig macht, gerade auch weil viele Länder große sprachliche Vielfalt aufweisen. Papua-Neuguinea etwa weist über 800 verschiedene Sprachen auf, was eine besonders komplexe innere Sprachstruktur darstellt. Für eine umfassendere Einsicht in die Kommunikationslandschaft wurden zudem Indizes für erlernte Sprachen entwickelt, die sogenannte Common Acquired Language (CAL)-Indizes.
Diese spiegeln die Anzahl und Verteilung von Zweit- oder Fremdsprachensprechern wider und geben Aufschluss über globale Verständigungsmittel wie Englisch oder Spanisch, die als Brückensprachen zahlreiche Länder verbinden. Ein weiterer Index kombiniert Mutter- und erlernte Sprachen, um die Gesamtheit aller sprachlichen Verbindungen zu erfassen und damit die tatsächliche Erreichbarkeit zwischen Bevölkerungen realistisch abzubilden. Ein besonders innovativer Beitrag des Datensatzes sind die Sprachproximity-Indizes – sowohl linguistische als auch verzweigungsspezifische. Diese Indizes messen die Nähe zwischen unterschiedlichen Sprachen auf Basis von linguistischen Familienbäumen. Sprachfamilien werden hier als evolutionäre Abstammungslinien dargestellt, die Aufschluss über den gemeinsamen Ursprung verschiedener Sprachen geben.
Eine hohe sprachliche Proximität deutet demnach auf verwandte Sprachen hin, die sich häufig in Aussprache, Grammatik oder Wortschatz ähneln und häufig zumindest teilweise gegenseitig verständlich sind. Solche Beziehungen sind besonders relevant für die Analyse von Regionen mit großer Sprachenvielfalt, in denen Kommunikationsbarrieren dennoch durch verwandte Sprachen reduziert werden können. Auf Basis dieses umfassenden Sets sprachlicher Verbindungsmaße bietet sich ein differenziertes Bild der globalen Sprachlandschaft. Während viele Länder starke sprachliche Beziehungen zu einer Vielzahl anderer Staaten aufweisen, etwa durch die Verbreitung globaler Verkehrssprachen wie Englisch, Mandarin oder Spanisch, sind andere Länder sprachlich relativ isoliert. Sprachliche Isolation kann etwa bei Regionen vorliegen, deren Sprachen keine nahen Verwandten haben oder die kaum als Amtssprache international verbreitet sind.
Dies findet sich häufig in Ländern mit vielen indigenen Sprachen oder spezifischen Sprachfamilien wie einigen Regionen in Asien und Afrika. Die statistische Analyse zeigt, dass die meisten Länderpaare geringe Werte bei den einzelnen Indizes aufweisen, was auf die sprachliche Heterogenität und Vielfalt weltweit hinweist. Gleichzeitig sorgen die Unterschiede in den Maßstäben – von offiziellen Sprachen bis zu Zweitsprachkenntnissen und proximale Ähnlichkeiten – für ein vielschichtiges Verständnis sprachlicher Verbindungen. Die einzelnen Indizes korrelieren teilweise nur schwach miteinander, was verdeutlicht, dass verschiedene Indikatoren unterschiedliche Aspekte der sprachlichen Realität erfassen. Ein weiterer wichtiger Aspekt des Datensatzes ist seine Validierung.
Er wurde mit anderen international anerkannten sprachlichen Datenquellen verglichen, was eine gute Übereinstimmung bei technisch vergleichbaren Indikatoren zeigt. Gleichzeitig wurden typische sprachliche Muster bestätigt, etwa die hohe Konnektivität von Ländern mit großen Mehrsprachigkeitsraten oder die geringe Verbindung von sprachlich isolierten Staaten. In empirischen Studien hat sich gezeigt, dass die Indizes des Datensatzes in Modellen zur Erklärung von Handelsströmen, Migration oder auch kulturellen Ähnlichkeiten zuverlässige und signifikante Effekte liefern. Durch ihren offenen Zugang über Plattformen wie der Harvard Dataverse und das USITC Gravity Portal sind die Daten für Forschung und Analyse leicht verfügbar. Die Daten liegen in einem strukturierten CSV-Format vor und eignen sich für eine einfache Verknüpfung mit ökonomischen und geographischen Informationen, was umfangreiche interdisziplinäre Anwendungen ermöglicht.
Die Verwendung einheitlicher Länderkennungen (ISO 3-Buchstaben-Codes) erleichtert die Integration zusätzlich. Die Weiterentwicklung des Datensatzes zeigt, dass er stetig aktualisiert und verfeinert wird. Neben Erweiterungen durch zusätzliche linguistische Indizes wurden auch methodische Korrekturen vorgenommen, um die Genauigkeit zu verbessern. Das mitgelieferte Python-Skript zur Datenaufbereitung bietet Forschern einen Einblick in die Berechnungsmethoden und unterstützt individuelle Anpassungen. Insgesamt stellt das Dataset zur linguistischen Vernetzung ein leistungsfähiges Werkzeug zur Erforschung globaler Sprachverhältnisse dar.