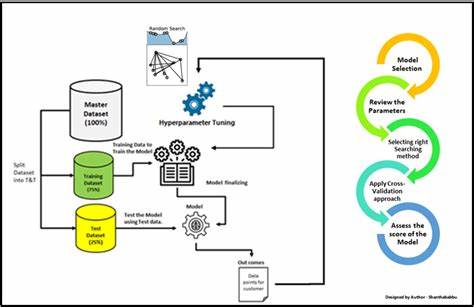
Die Entwicklung leistungsfähiger Modelle im Bereich des maschinellen Lernens hängt oft maßgeblich von der richtigen Wahl der Hyperparameter ab. Hyperparameter sind jene Einstellungen, die vor dem Trainingsprozess eines Modells festgelegt werden und maßgeblich dessen Leistung beeinflussen können. Zu ihnen zählen beispielsweise die Lernrate, die Batch-Größe oder die Anzahl der Schichten in einem neuronalen Netzwerk. Doch im Gegensatz zu den Modellparametern, die während des Trainings gelernt werden, müssen Hyperparameter vorab definiert und optimiert werden – eine Aufgabe, die sowohl zeit- als auch ressourcenintensiv ist. Das traditionelle Verständnis von Hyperparameter-Tuning konzentriert sich häufig auf das Probieren verschiedener Kombinationen in einem mehr oder weniger systematischen Suchprozess.
Grid Search und Random Search sind zwei bekannte Methoden, mit denen versucht wird, die optimale Konfiguration zu finden. Grid Search definiert dabei ein Raster aus verschiedenen Werten aller Hyperparameter und testet jede Kombination nacheinander. Random Search probiert zufällige Kombinationen innerhalb des definierten Suchraums aus. Allerdings sticht bei beiden Verfahren schnell die enorm hohe Rechenintensität hervor, vor allem wenn komplexe Modelle oder große Datensätze zum Einsatz kommen. Vor diesem Hintergrund gewinnt ein neuer Blickwinkel zunehmend an Bedeutung: Hyperparameter-Tuning als ein Problem der Ressourcenplanung zu sehen.
Diese Betrachtungsweise rückt die Limitierungen der verfügbaren Zeit und Rechenleistung in den Mittelpunkt und behandelt das Optimierungsverfahren als eine Art Scheduling-Problem. Hierbei geht es nicht einfach nur darum, möglichst viele Hyperparameter-Kombinationen zu testen, sondern vielmehr darum, mit begrenzten Ressourcen gezielt und effizient zu entscheiden, welche Experimente durchgeführt, früh abgebrochen oder intensiviert werden sollen. In der Praxis bedeutet das, dass das Training eines Modells mit einer bestimmten Hyperparameter-Kombination häufig viel Zeit in Anspruch nimmt. Daher ist es entscheidend, solche Konfigurationen möglichst früh zu identifizieren, die vielversprechend sind und ihnen mehr Ressourcen zuzuteilen. Gleichzeitig sollten solche, die schlechte Ergebnisse liefern, frühzeitig beendet werden, um Rechenkapazitäten freizugeben.
Dieses Vorgehen hat viel Ähnlichkeit mit der Planung und Verwaltung von Aufgaben in einem System mit begrenzter Kapazität, in welchem Entscheidungen über Priorisierung, Abbruch oder Vertiefung getroffen werden müssen. Es existieren bereits verschiedene fortgeschrittene Algorithmen, die genau diese ressourcenorientierte Sichtweise umsetzen. Ein bekanntes Beispiel ist ASHA, die Asynchronous Successive Halving Algorithmus. ASHA startet mehrere Trainingsläufe mit minimalem Ressourceneinsatz und eliminiert kontinuierlich die weniger erfolgreichen Konfigurationen, während die vielversprechenden mit mehr Rechenkapazitäten weitertrainiert werden. Dabei wird auch die Parallelität genutzt, um mehrere Experimente gleichzeitig durchzuführen, was die Gesamtlaufzeit signifikant verkürzen kann.
Hyperband ist eine weitere Methode, die das Prinzip von Successive Halving weiterentwickelt und in mehreren parallelen Pfaden verschiedene Ressourcenzuteilungen erprobt. Diese Kombination aus Exploration und Ausbeutung sorgt für eine ausgewogene Suche im Hyperparameter-Raum und optimiert zugleich die Ressourcennutzung, indem die Rechenzeit vor allem auf die erfolgversprechendsten Versuche konzentriert wird. Ein noch weitergehender Ansatz ist das Population-Based Training (PBT), bei dem eine Population von Modellen parallel trainiert wird. Dabei werden nicht nur die Hyperparameter nach einer gewissen Trainingszeit angepasst und weiterentwickelt, sondern auch unter den Modellen ausgetauscht und mutiert, ähnlich evolutionärer Algorithmen. So verbindet PBT das kontinuierliche Lernen der Modellparameter mit der dynamischen Anpassung der Hyperparameter und fördert zudem eine effiziente Nutzung der verfügbaren Ressourcen.
Die Bedeutung dieser ressourcenbasierten Optimierungsstrategien liegt auf mehreren Ebenen. Zum einen unterstützen sie dabei, die Trainingszeit zu verkürzen und die Kosten für Hardware-Ressourcen zu reduzieren. Gerade bei komplexen Modellen und großen Datensätzen sind diese Optimierungen oft entscheidend, um überhaupt praktikable Ergebniszeiten zu erreichen. Zum anderen ermöglichen sie eine bessere Handhabung des Spannungsfelds zwischen Exploration und Exploitation: Zuerst sollten möglichst viele unterschiedliche Bereiche des Hyperparameter-Raumes getestet werden, um eine grobe Orientierung über erfolgversprechende Regionen zu erhalten. Im Anschluss wird dann der Fokus auf die Feinjustierung und intensive Optimierung der besten Kandidaten gelegt.
Gerade im industriellen Umfeld, in dem Modelle häufig in produktiven Systemen eingesetzt werden müssen und schnelle Iterationen gefragt sind, ist die effiziente Ressourcensteuerung essenziell. Hier zeigen sich Parallelen zu klassischen Scheduling-Problemen in der Informatik, beispielsweise der Verwaltung von Computerjobs unter Limitierungen wie CPU, Speicher oder Zeitfenstern. Durch diesen zielführenden Vergleich können bewährte Ansätze aus dem Scheduling-Bereich adaptiv für Hyperparameter-Tuning genutzt und weiterentwickelt werden. Ausblickend gewinnt die Integration von Meta-Learning in den Bereich des Hyperparameter-Tunings zunehmend an Bedeutung. Meta-Learning nutzt Erfahrungen aus vorherigen Optimierungen, um neue Optimierungszyklen effizienter zu gestalten.
Dabei wird nicht nur das aktuelle Ressourcenmanagement verbessert, sondern auch eine intelligentere Vorauswahl der Hyperparameter möglich. Ebenso bieten evolutionäre Algorithmen und deren Weiterentwicklungen die Chance, komplexe Hyperparameterlandschaften adaptiv und robust zu erforschen, wobei dynamische Ressourcenallokationen und kontinuierliche Lernprozesse ineinandergreifen. Zusammenfassend lässt sich sagen, dass die Sichtweise von Hyperparameter-Tuning als Ressourcenplanungsproblem eine neue Dimension eröffnet, die über das reine Durchprobieren von Kombinationen deutlich hinausgeht. Durch intelligente Scheduling-Strategien und adaptive Ressourcenzuweisung können sehr viel bessere Ergebnisse in kürzerer Zeit erzielt werden. Diese Perspektive fördert nicht nur die Effizienz, sondern auch die Praktikabilität von maschinellem Lernen in großem Maßstab und komplexen Anwendungsfällen.
Die Zukunft der Hyperparameter-Optimierung liegt damit klar in der symbiotischen Verbindung von algorithmischer Intelligenz und effektivem Ressourcenmanagement.