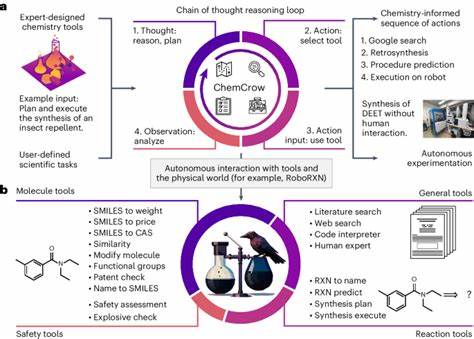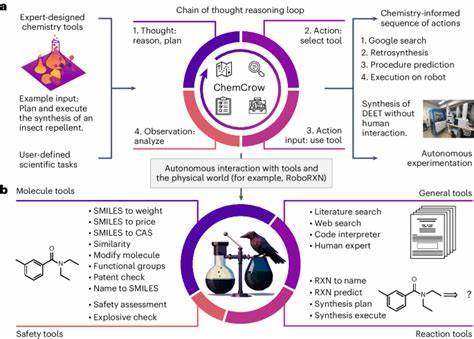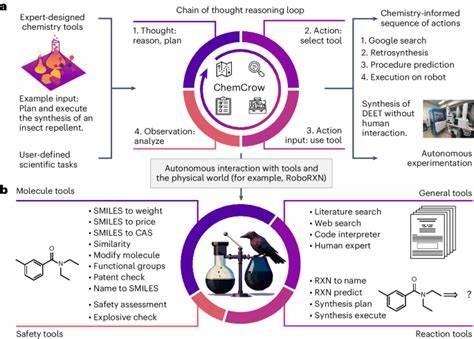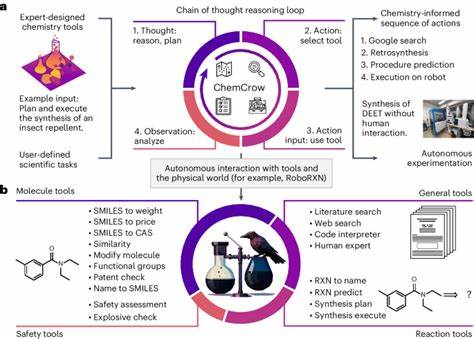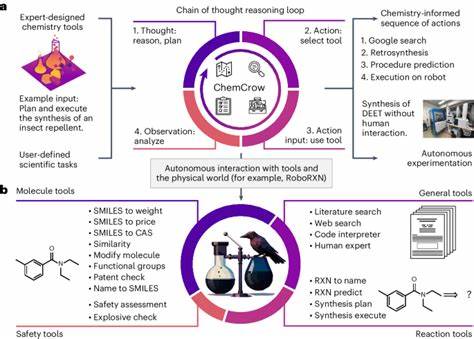
Die rasante Entwicklung großer Sprachmodelle, auch bekannt als Large Language Models (LLMs), hat in den letzten Jahren die wissenschaftliche Gemeinschaft und speziell die Chemie stark beeinflusst. Ursprünglich wurden diese Modelle vor allem für allgemeinsprachliche Aufgaben entwickelt, doch ihr Einsatzgebiet hat sich inzwischen massiv ausgeweitet. In der Chemie eröffnen sie völlig neue Möglichkeiten – von der schnellen Beantwortung komplexer Fragestellungen bis hin zur Unterstützung bei der Planung von Experimenten. Doch stellt sich die essenzielle Frage: Wie stehen diese KI-Modelle im Vergleich zur fachlichen Expertise erfahrener Chemiker? Aktuelle Forschungsarbeiten haben begonnen, eine systematische Bewertung der chemischen Wissens- und Argumentationsfähigkeiten von LLMs gegen die Kompetenz von menschlichen Experten vorzunehmen. Ein herausragendes Beispiel bietet das ChemBench-Projekt, das eine umfangreiche Datenbank mit fast 2.
800 Frage-Antwort-Paaren aus den verschiedensten Bereichen der Chemie zusammengestellt hat. Darin spiegeln sich sowohl einfache Wissensfragen als auch komplexe Problemlösungs- und Argumentationsaufgaben wider, die von Grundlagen der allgemeinen Chemie bis hin zu Spezialgebieten wie organischer Analyse und Toxikologie reichen. Die Erkenntnisse aus den Tests klingen auf den ersten Blick beeindruckend: Einige der fortschrittlichsten LLMs übertrafen im Mittel die Leistung der befragten Chemiker in diversen Teilbereichen der Chemie erheblich. Dabei wurden sogar Modelle aus dem Open-Source-Bereich erwähnt, die mit kommerziellen Systemen konkurrieren können. Diese Entwicklung verdeutlicht, dass die schiere Datenmenge und das Training auf wissenschaftlichen Texten, gepaart mit enormer Rechenleistung und optimierter Architektur, dazu beitragen, dass LLMs nicht nur Fakten reproduzieren, sondern teils überraschend klug kombinieren und folgern.
Nicht zu unterschätzen sind jedoch die Schwächen und Grenzen dieser Technologie. Oft scheitern die Modelle an scheinbar simplen Grundfragen oder an der sicheren Einschätzung der Richtigkeit ihrer Antworten. Besonders auffällig ist ihre neigung zu "überconfidenten" Antworten, das heißt, sie geben häufig die Antwort mit großer Sicherheit an, auch wenn diese falsch ist. In der Chemie kann das gefährlich sein, vor allem wenn es um Sicherheit oder Toxizität von Substanzen geht. Darüber hinaus zeigt sich, dass viele Probleme der LLMs darin begründet sind, dass sie nicht tatsächlich die molekulare Struktur oder Komplexität physikalisch und chemisch „verstehen“.
Stattdessen basiert vieles auf der Ähnlichkeit zu bereits gelernten Datenpunkten oder Mustern. So beispielsweise bei der Vorhersage von NMR-Signalen, die für menschliche Experten oft eine Interpretation der Molekülgeometrie erfordert. Die Modelle können Strukturdarstellungen, wie die SMILES-Notation, zwar lesen und verarbeiten, doch fehlt ihnen die echte räumliche Interpretation, die chemische Vernunft vielfach verlangt. Ein weiterer wichtiger Punkt ist der Umgang mit chemischer Intuition und Präferenzen. Chemiker entscheiden oft nicht nur aufgrund harter Fakten, sondern auch aufgrund von Erfahrung und sogenannter chemischer Intuition, etwa im frühen Stadium von Wirkstoffentwicklungen.
In diesen Aspekten zeigen die aktuellen Sprachmodelle große Defizite, da sie keine ‚echte‘ Präferenzbildung leisten können und oft Ergebnisse liefern, die statistisch wirken, ohne mit menschlichen Vorlieben übereinzustimmen. Die Implikationen solcher Ergebnisse sind weitreichend. Die Überlegenheit der LLMs bei der schnellen Wiedergabe und Bearbeitung von kontextuellem Wissen könnte die Arbeitsweise von Chemikern verändern. Chemiker könnten sich zukünftig vermehrt auf die Interpretation, kritische Überprüfung und kreative Weiterentwicklung von Ideen konzentrieren, während Routineaufgaben von KI-Systemen übernommen werden. Doch darauf weist die aktuelle Forschung auch hin: Chemie-Ausbildung und Prüfungen müssen neu gedacht werden.
Das reine Auswendiglernen und statische Wissen verlieren an Bedeutung; vielmehr rückt das Verständnis, das kritische Denken und die Fähigkeit, den Output von KI-Systemen zu hinterfragen, in den Vordergrund. Mittels frameworks wie ChemBench kann die Entwicklung von Chemie-LLMs systematisch verfolgt und transparent dargestellt werden. Die Evaluierung bietet zudem eine Grundlage, um die Modelle künftig besser an die Bedürfnisse der chemischen Wissenschaft anzupassen. Kritikfähige KI-Systeme könnten eventuell durch die Kombination aus großem Datenzugang, spezialisierten Datenbanken und multimodalen Fähigkeiten (beispielsweise zum besseren Umgang mit chemischen Strukturen und Formeln) wesentlich verbessert werden. Es besteht zudem ein Bedarf an Methoden, welche die Ungewissheit und Vertrauenswürdigkeit der Vorhersagen der KI deutlich kommunizieren, um Fehlentscheidungen und potenzielle Risiken zu minimieren.
Auch die gesellschaftlichen Auswirkungen sind bedeutend. KI-Systeme sind heute leicht zugänglich und könnten etwa von Studierenden oder dem allgemeinen Publikum genutzt werden, um Chemie-Fragen zu stellen. Dabei besteht die Gefahr, dass falsche oder unsichere Antworten Vertrauen erschüttern oder sogar zu gefährlichen Anwendungen führen. Verlässliche und sichere KI-Systeme erfordern daher aufwändige Sicherheitsmechanismen und den verantwortungsvollen Umgang mit den generierten Informationen. Ausblickend lässt sich sagen, dass große Sprachmodelle eine faszinierende Entwicklung für den Bereich der Chemie und der naturwissenschaftlichen Forschung insgesamt darstellen.
Sie ermöglichen erhebliche Zeitersparnisse, Unterstützung bei der Informationsverarbeitung und beeinflussen die Art und Weise, wie Wissen erschlossen wird. Gleichzeitig unterstreichen die Erkenntnisse aus Studien wie ChemBench, dass es noch längere Zeit menschlicher Expertise bedarf, um die Grenzen der Artefakte aufzuzeigen und verantwortungsvoll mit ihnen umzugehen. Die Zukunft wird vermutlich eine intensive Zusammenarbeit zwischen künstlicher und menschlicher Intelligenz sein, bei der die Stärken beider Seiten genutzt werden. Chemiker und KI-Systeme ergänzen sich, indem KI Wissensquellen und Berechnungen blitzschnell bereitstellt und der Chemiker mit Erfahrung, Kreativität und kritischem Denken die richtigen Schlüsse zieht. Ein weiteres spannendes Feld ist die Integration von multimodalen KI-Modellen, die nicht nur Texte, sondern auch Bilder, Diagramme und molekulare Darstellungen verstehen und interpretieren können – was besonders in der Chemie von großer Bedeutung ist.
Zusammenfassend zeigt sich, dass die chemische Wissensbasis und die Fähigkeit zum logischen Denken großer Sprachmodelle bereits bemerkenswerte Leistungen erzielen. Dennoch stellen spezifische Herausforderungen wie die tiefere molekulare Erkenntnis, die Einschätzung eigener Unsicherheiten und die chemische Intuition Hemmnisse dar. Die Erforschung und Weiterentwicklung in diesem Bereich ist hochaktuell und wird die artifizielle Intelligenz im Kontext chemischer Wissenschaften maßgeblich prägen – mit weitreichenden Konsequenzen für Bildung, Forschung und Anwendung. Die Diskussion um die Rolle großer Sprachmodelle in der Chemie ist daher nicht nur akademisch, sondern berührt Ethik, Ausbildung, Technologieregulierung und Sicherheitsfragen gleichermaßen. Gleichzeitig bieten der offene Zugang zu Datensätzen und Benchmarking-Frameworks wie ChemBench eine wertvolle Basis für eine transparente, offene und verantwortungsbewusste Weiterentwicklung dieser Technologie.
Es ist zu erwarten, dass die Fortschritte in den kommenden Jahren zu einem Umbruch führen könnten, der die Chemie nachhaltig verändert und neue Wege ermöglicht, Wissen zu entdecken und Wissen umzusetzen – stets unter der Prämisse, dass menschliche Expertise und kritische Reflexion unverzichtbar bleiben.