Die rasante Entwicklung im Bereich des maschinellen Lernens hat zu immer größeren und komplexeren neuronalen Netzwerken geführt. Besonders im Bereich der natürlichen Sprachverarbeitung und der Bildverarbeitung sind Modelle mit Milliarden von Parametern keine Seltenheit mehr. Mit zunehmender Modellgröße steigen jedoch auch die Anforderungen an Rechenressourcen und die Komplexität der Hyperparameteroptimierung. In diesem Zusammenhang gewinnt das Konzept der Zero-Shot Hyperparameter Transfer Methode an Bedeutung, die es ermöglicht, die Hyperparameter von kleinen Modellen erfolgreich auf wesentlich größere Netzwerke zu übertragen, ohne dass umfangreiche Neutrainings oder zeitraubende Suchverfahren erforderlich sind. Ein wesentlicher Baustein dieser Methodik ist die sogenannte maximale Update-Parametrisierung, auch bekannt als μP.
Maximale Update-Parametrisierung (μP) stellt eine neue parametrische Strategie dar, welche die Stabilität und Skalierbarkeit großer neuronaler Netzwerke signifikant verbessert. Ein zentrales Problem beim Skalieren von Netzwerken besteht darin, dass sich optimale Hyperparameter wie Lernrate, Initialisierungen oder Gewichtungsfaktoren mit zunehmender Breite oder Tiefe stark verändern. Diese Variabilität führt häufig zu instabilen Trainingsprozessen und erschwert die effektive Nutzung großer Modelle. Die μP-Methode löst dies, indem sie eine spezielle Skalierung der Parameter und Optimierungsverfahren sicherstellt, welche dazu führt, dass sich die optimalen Hyperparameter kaum mit der Netzwerkgröße verändern. Dieses sogenannte Hyperparameter-Stabilitätsprinzip ist eine fundamentale Eigenschaft von μP, die Zero-Shot Hyperparameter Transfer erst ermöglicht.
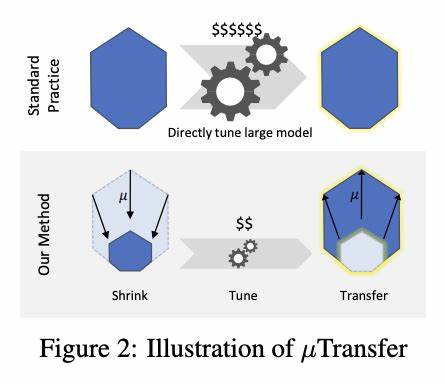
Die Anwendung von Zero-Shot Hyperparameter Transfer in Verbindung mit μP eröffnet potenziell revolutionäre Möglichkeiten in der Deep Learning-Forschung und -Praxis. Indem die optimalen Hyperparameter an einem kleinen Basis-Modell abgestimmt werden können, lässt sich diese Konfiguration auf ein deutlich größeres Zielmodell übertragen. Diese Übertragung erfolgt ganz ohne weitere Hyperparameter-Suche für das große Modell – daher der Begriff „Zero-Shot“. Diese Fähigkeit spart enorme Mengen an Rechenleistung und Zeit, was für Unternehmen und Forschungseinrichtungen, die mit beschränkten Ressourcen arbeiten, von großem Vorteil ist. Zudem reduziert die Methode die Unsicherheit und das Risiko, dass bei der Skalierung Probleme auftreten, da die Parameterharmonie bereits auf kleinen Modellen gewährleistet wurde.
Technisch gesehen basiert die Umsetzung von μP auf einer genauen Analyse der mathematischen Wirkung von Parameter- und Lernraten-Skalierungen bei der skalierenden Netzwerkbreite. Dabei wird berücksichtigt, wie sich die Koordinaten von Aktivierungen und Gradienten im Rahmen von Vorwärts- und Rückwärtsdurchläufen verändern. Von besonderem Interesse ist die sogenannte „Koordinatenstabilität“, die sich bei korrekter Anwendung von μP über verschiedene Modellgrößen hinweg einstellt. Diese Stabilität kann mit Koordinaten-Checks verifiziert werden, einem diagnostischen Verfahren, das sicherstellt, dass die Größenordnung der Aktivierungen und Gradienten in verschiedenen Schichten und Breiten des Netzwerks konsistent bleibt. Ein einfaches Beispiel ist die Überprüfung, dass die durchschnittliche Größe der Koordinaten von Aktivierungsvektoren bei Änderung der Netzwerkbreite konstant bleibt.
Ist dies der Fall, deutet dies darauf hin, dass die Parametrisierung korrekt ausgeführt wurde und somit Hyperparameter stabilisiert sind. Die Implementierung von μP und Zero-Shot Hyperparameter Transfer wird durch spezialisierte Tools wie das Open-Source-Paket „mup“ von Microsoft erleichtert. Dieses Paket bietet eine Reihe von Funktionen, um Modelle in PyTorch entsprechend zu parametrisieren und die korrekte Skalierung von Lernraten und Initialisierungen automatisch durchzuführen. Nutzer können so große vortrainierte Modelle oder selbstentwickelte Architekturen problemlos auf μP umstellen, ohne tiefgreifende manuelle Eingriffe vornehmen zu müssen. Ein Kernfeature dabei ist die Definition von sogenannten „Base Models“ und „Delta Models“, die als Referenz-Punkte für die Exemplare unterschiedlicher Breiten dienen, um die interne Abstimmung der Parameterformen und Optimierer durchzuführen.
Eine weitere Herausforderung, die im Zuge dieser Methode adressiert wird, ist die Integration mit existierenden Trainingsparadigmen wie verteiltem Training und Learning-Rate Scheduling. Dabei sind bestimmte Einschränkungen zu beachten – beispielsweise funktioniert die Skalierung nicht kompatibel mit allen Parallelisierungsstrategien wie „torch.nn.DataParallel“. Stattdessen wird „DistributedDataParallel“ empfohlen, um den Verlust von Informationen über Parametereigenschaften zu vermeiden.
Gleiches gilt für Learning-Rate-Scheduler – bei der Verwendung von Spezialoptimierern aus mup muss darauf geachtet werden, dass Scheduler relative Anpassungen der Lernrate vornehmen, statt absolute Werte einzustellen, um die Skalierung korrekt zu erhalten. Die Bedeutung von μP geht über die reine Hyperparameter-Transferleistung hinaus. Sie adressiert grundsätzliche Fragestellungen zu den physikalischen und mathematischen Eigenschaften von neuronalen Netzwerken bei zunehmender Größe. Häufig entstehen Phänomene wie das Explodieren oder Verschwinden von Gradienten sowie inkonsistente Signalstärken in tiefen Schichten großer Modelle. Die maximal mögliche Skalierung von Parameterupdates ohne Instabilität ist genau der Punkt, den μP definiert und anvisiert.
Dies steigert nicht nur die Trainingsstabilität, sondern führt auch zu besseren Generalisierungseigenschaften und einer effizienteren Nutzung der Modellkapazität. Im praktischen Einsatz ermöglicht die Kombination von μP mit Zero-Shot Hyperparameter Transfer die problemlose Übertragung aus kleineren Dimensionierungen, basierend auf maßgeschneiderten Experimenten oder Benchmarks. Entwickler können somit etwa auf einem kleinen Modellsetting verschiedene Lernraten, Initialisierungen oder Optimierer testen und die besten Konfigurationen auf ein wesentlich größeres Modell übertragen. Diese Vorgehensweise beseitigt die oft unpraktische Hürde des Suchens im Hyperparameterraum großer Modelle, das traditionell oft Wochen oder Monate in Anspruch nehmen kann. Außerdem fördert diese Methodik die Nachhaltigkeit und Ressourceneffizienz im Deep Learning erheblich.
Da der Rechenaufwand für Hyperparameter-Tuning drastisch reduziert wird, sinken auch die benötigten Energiekosten und der ökologische Fußabdruck vergleichbarer Experimente. Gerade bei der industriellen Nutzung großer vortrainierter Transformer-Modelle wird so ein nachhaltigerer und wirtschaftlicherer Betrieb möglich. Ein weiterer praktischer Aspekt ist die Kompatibilität von μP mit modernsten Modellarchitekturen, inklusive Transformers, ResNets und MLPs. Das mup-Paket enthält bereits diverse Beispielimplementierungen sowie Testing-Module, die die korrekte Anwendung der Methode veranschaulichen. Für Nutzer von Huggingface Transformer Models, die mit Skalierungsproblemen kämpfen, stellt μP eine adressierbare Lösung dar, die per Plug-and-Play teilweise sogar ohne Änderung am Modellcode funktioniert – abgesehen von der Anwendung spezieller Initialisierungen und Optimierer, die vom Framework bereitgestellt werden.
Trotz der vielen Vorteile ist es wichtig, die derzeitigen Limitationen von μP und Zero-Shot Hyperparameter Transfer zu berücksichtigen. So bedarf es sorgfältiger Einrichtung der Base- und Delta-Modelle, und es wird vorausgesetzt, dass das ursprüngliche Modell mit den typischen PyTorch-Initialisierungen erzeugt wurde. Die Integration in hochgradig modifizierte Modelle oder exotische Architekturen kann zusätzlichen Aufwand verursachen. Zudem werden noch Arbeiten daran getan, die Kompatibilität mit Speichersystemen wie beim Laden und Speichern von Checkpoints mit Infshape-Informationen nahtlos zu gestalten, ohne dass stets eine nachträgliche erneute Parametrisierung nötig ist. Zusammenfassend ist die Kombination aus maximaler Update-Parametrisierung und Zero-Shot Hyperparameter Transfer ein vielversprechender Ansatz, um den Herausforderungen traditioneller Hyperparameteroptimierung bei großen neuronalen Netzwerken entgegenzuwirken.
Sie bietet eine mathematisch fundierte, praktisch anwendbare Methodik, die Skalierbarkeitsprobleme reduziert und Trainingsprozesse stabilisiert. Die schnelle und unkomplizierte Portierung von Hyperparametern vom kleinen Modell auf das große vereinfacht Entwicklungszyklen und senkt den Ressourcenverbrauch erheblich. Branchen und Forschungsbereiche, die von dieser Methodik profitieren, sind vielfältig. Angefangen von der Verarbeitung natürlicher Sprache mit großen Sprachmodellen über Computer Vision bis hin zu generativen Modellen in Kunst und Wissenschaft lassen sich die Prinzipien von μP effektiv anwenden. Die zunehmende Offenlegung von Implementationen und begleitenden Open-Source-Tools unterstützt zudem die breite Nutzung dieser technologischen Neuerung.
Es bleibt spannend, wie sich die Weiterentwicklung der parametrischen Paradigmen und zugehöriger Transfermethoden auf die zukünftige Generation großer neuronaler Netze auswirkt. Höhere Effizienz, stabilere Trainingsprozesse und reduzierte Abhängigkeit von aufwendiger Hyperparameter-Suche sind wesentliche Fortschritte, die mit großer Wahrscheinlichkeit tiefgreifende Veränderungen im Deep Learning Ökosystem bewirken werden. Anwender, Forscher und Entwickler sind eingeladen, μP und Zero-Shot Hyperparameter Transfer in ihren eigenen Projekten zu testen und weiterzuentwickeln, um die Methode noch robuster und vielseitiger zu gestalten.


![Getting better at LLMs, with Zvi Mowshowitz [audio]](/images/62A34348-7DA1-4446-A41B-A1ECB8F49C64)





